查漏补缺
一、Java
1、Java中数组和List的转换
(1)数组转链表 Arrays.asList(array)
Integer[] array = {1,3,4,6};
ArrayList<Integer> list= new ArrayList<>(Arrays.asList(array));
System.out.print(list);
输出[1, 3, 4, 6]
(2)链表转数组list.toArray(array)
ArrayList<Integer> list= new ArrayList<>();
list.add(1);
list.add(2);
list.add(4);
list.add(6);
Integer[] array = new Integer[list.size()];
list.toArray(array);
System.out.print(Arrays.toString(array));
2、成员变量也称属性,是事物静态特征的抽象。成员变量分为两种:类的成员变量和对象的成员变量(又称为实例变量)
3、instanceof关键字在Java中用于判断一个对象是否属于某个特定类的实例,并且返回boolean类型的返回值。
4、Collection 接口常用的方法:
size():返回集合中元素的个数
add(Object obj):向集合中添加一个元素
addAll(Colletion coll):将形参coll包含的所有元素添加到当前集合中
isEmpty():判断这个集合是否为空
clear():清空集合元素
contains(Object obj):判断集合中是否包含指定的obj元素
① 判断的依据:根据元素所在类的equals()方法进行判断
② 明确:如果存入集合中的元素是自定义的类对象,要去:自定义类要重写equals()方法
constainsAll(Collection coll):判断当前集合中是否包含coll的所有元素
rentainAll(Collection coll):求当前集合与coll的共有集合,返回给当前集合
remove(Object obj):删除集合中obj元素,若删除成功,返回ture否则
removeAll(Collection coll):从当前集合中删除包含coll的元素
equals(Object obj):判断集合中的所有元素 是否相同
hashCode():返回集合的哈希值
toArray(T[] a):将集合转化为数组,如有参数,返回数组的运行时类型与指定数组的运行时类型相同。
iterator():返回一个Iterator接口实现类的对象,进而实现集合的遍历。
数组转换为集合:Arrays.asList(数组)
5、如果try语句里有return(finally和catch中没有return),返回的是try语句块中变量值(finally{}代码块比try和catch中的return先执行,try和catch中的return先保存结果,等finally执行完后再返回结果)。详细执行过程如下:
如果有返回值,就把返回值保存到局部变量中;
执行jsr指令跳到finally语句里执行;
执行完finally语句后,返回之前保存在局部变量表里的值。
**如果try,finally语句里均有return,忽略try的return,而使用finally的return。**finally语句先于try和catch中的return和throw语句执行。
6、Servlet生命周期分成3个阶段:
初始化阶段:调用init方法 响应客户请求:调用service 终止:调用destory方法
7、Servlet过滤器的配置包括两部分: 第一部分是过滤器在Web应用中的定义,由<filter>元素表示,包括<filter-name>和<filter-class>两个必需的子元素 第二部分是过滤器映射的定义,由<filter-mapping>元素表示,可以将一个过滤器映射到一个或者多个Servlet或JSP文件,也可以采用url-pattern将过滤器映射到任意特征的URL。
8、input和output指的是对于程序而言。input是从文件读取进来,output是输出到文件。
9、getParameter()是获取POST/GET传递的参数值; getInitParameter获取Tomcat的server.xml中设置Context的初始化参数 getAttribute()是获取对象容器中的数据值; getRequestDispatcher是请求转发。
10、在Web开发中有四种方法可以实现会话跟踪技术:URL重写、隐藏表单域、Cookie、Session。
11、方法重写的两同两小一大原则: 方法名相同,参数类型相同 子类返回类型小于等于父类方法返回类型, 子类抛出异常小于等于父类方法抛出异常, 子类访问权限大于等于父类方法访问权限。
12、Java中的ClassLoader(类加载器)
默认情况下,Java应用启动过程涉及三个ClassLoader: Boostrap, Extension, System;类装载器需要保证类装载过程的线程安全;ClassLoader的父子结构中,默认装载采用了父优先;
13、final修饰方法后,方法是不可被重写的,但可以重载。
14、this用于重载构造器,super用于调用父类被子类重写的方法,都要放在第一行。无论是this()还是super()指的都是对象,而static环境中是无法使用非静态变量的。 super和this不能同时使用,这是因为会造成初始化两次。
15、二维数组的声明
int a[][] = new int[10][10];
int []b[] = new int[10][10];
int [][]c = new int[10][10];
16、三维数组的声明
int a[][][] = new int[2][3][4];
int []b[][] = new int[2][3][4];
int [][]c[] = new int[2][3][4];
int [][][]d = new int[2][3][4];
17、为了降低模块的耦合性,应优先选用接口,尽量少用抽象类;抽象类和接口都不能被实例化;接口和抽象类都可以被声明使用。
18、程序计数器是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的信号指示器,每个线程都需要一个独立的程序计数器; 方法区是各个线程共享的内存区域,它用于存储已经被虚拟机加载的常量、即时编译器编译后的代码、静态变量等数据。
19、中间件位于操作系统之上,应用软件之下,而不是操作系统内核中。
20、Collection是java.util下的接口,它是各种集合结构的父接口(但注意Map没有实现Collection,但是Map也是集合,所以这个讲述不那么准确);Collections是java.util下的类,它包含有各种有关集合操作的静态方法
21、is-a 表示继承:Gadget is-a Widget就表示Gadget 继承 Widget; has-a表示从属:Gadget has-a Sprocket就表示Gadget中有Sprocket的引用,Sprocket是Gadget的组成部分; like-a表示组合:如果A like-a B,那么B就是A的接口; use-a 表示依赖
22、synchronized修饰非静态方法 锁的是this 对象;修饰静态方法锁的是class对象。
23、

24、在异常处理中,若try中的代码可能产生多种异常则可以对应多个catch语句,若catch中的参数类型有父类子类关系,此时应该将父类放在后面,子类放在前面。
25、Java中的byte,short,char进行计算时,若没有final修饰都会提升为int类型。
26、构造代码块在创建对象时被调用,每次创建对象都会被调用,并且构造代码块的执行次序优先于类构造函数。
27、abstract是用来修饰类和方法的:
修饰方法:abstract不能和private、final、static共用。 修饰外部类:abstract不能和final、static共用。(外部类的访问修饰符只能是默认和public)
修饰内部类:abstract不能和final共用。(内部类四种访问修饰符都可以修饰)
28、**不论向上或者向下转型,都是一句话,“编译看左边,运行看右边”。也就是编译时候,会看左边引用类型是否能正确编译通过,运行的时候是调用右边的对象的方法。**就本题来说,编译时候会发现左边满足条件所以编译通过,运行时候又会调用右边也就是 class B 的方法,所以答案都是150。
class A {
public int func1(int a, int b) {
return a - b;
}
}
class B extends A {
public int func1(int a, int b) {
return a + b;
}
}
public class ChildClass {
public static void main(String[] args) {
A a = new B();
B b = new B();
System.out.println("Result=" + a.func1(100, 50)); //输出Result=150
System.out.println("Result=" + b.func1(100, 50)); //输出Result=150
}
}
下面的代码编译不通过,原因:Base base = new Son(); 这句new 了一个派生类,赋值给基类,所以下面的操作编译器认为base对象就是Base类型的 Base类中不存在methodB()方法,所以编译不通过。向上转型,父类型引用指向子类对象,在编译期,编译器检查引用的类型,查找其方法,没有methodB(),不能通过编译。
class Base
{
public void method()
{
System.out.println("Base");
}
}
class Son extends Base
{
public void method()
{
System.out.println("Son");
}
public void methodB()
{
System.out.println("SonB");
}
}
public class Test01
{
public static void main(String[] args)
{
Base base = new Son(); //这句new 了一个派生类,赋值给基类
base.method();
base.methodB();
}
}
29、Java数据域就是成员变量,即属性。数据域可以是基本类型变量,也可以是一个对象。
30、抽象类可以实现接口而且可以继承自抽象类;抽象类必须有“abstract class”修饰;抽象类指有abstract修饰的class,其可以包含抽象方法,也可以不包含;抽象类和接口都是不能被实例化的,只有具体的类才可以被实例化。
31、javac 可以将java源文件编译为class字节码文件,如 javac HelloWorld.java,运行javac命令后,如果成功编译没有错误的话,会出现一个HelloWorld.class的文件。 java 可以运行class字节码文件,如 java HelloWorld。注意java命令后面不要加.class
32、Semaphore:类,控制某个资源可被同时访问的个数; ReentrantLock:类,具有与使用synchronized方法和语句所访问的隐式监视器锁相同的一些基本行为和语义,但功能更强大; Future:接口,表示异步计算的结果; CountDownLatch: 类,可以用来在一个线程中等待多个线程完成任务的类。
33、finally{}代码块比try和catch中的return先执行。
34、方法内定义的变量没有初始值,必须要进行初始化。 类中定义的变量可以不需要赋予初始值,有默认值。
35、 按位或| 按位且& 按位取反~ 按位异或^
逻辑与&& 逻辑或|| 非!
左移<<:补0,相当于乘以2 右移>>:补符号位,相当于除以2 无符号右移>>>:补0
注:左移一位时,当32位或者31位是1的话会溢出,结果就不是乘以2了。比如Integer.MAX_VALUE会溢出为-2,Integer.MIN_VALUE会溢出为0。
36、静态变量只能在类主体中定义,不能在方法中定义
37、floor: 求小于参数的最大整数。返回double类型,例如:Math.floor(-4.2) = -5.0 ceil: 求大于参数的最小整数。返回double类型,例如:Math.ceil(5.6) = 6.0 round: 对小数进行四舍五入后的结果。返回int类型,例如:Math.round(-4.6) = -5 random:随机生成区间[0,1)的浮点数
对于round,四舍六入,五往大的跑。
Math.round(-11.4) //-11
Math.round(-11.5) //-11
Math.round(-11.6) //-12
Math.round(-4.6) //-5
38、字符串在java中存储在字符串常量区中;
39、包装类的“==”运算在不遇到算术运算的情况下不会自动拆箱;包装类的equals()方法不处理数据转型。
40、ThreadLocal用于创建线程的本地变量,该变量是线程之间不共享的。
41、Java内部类
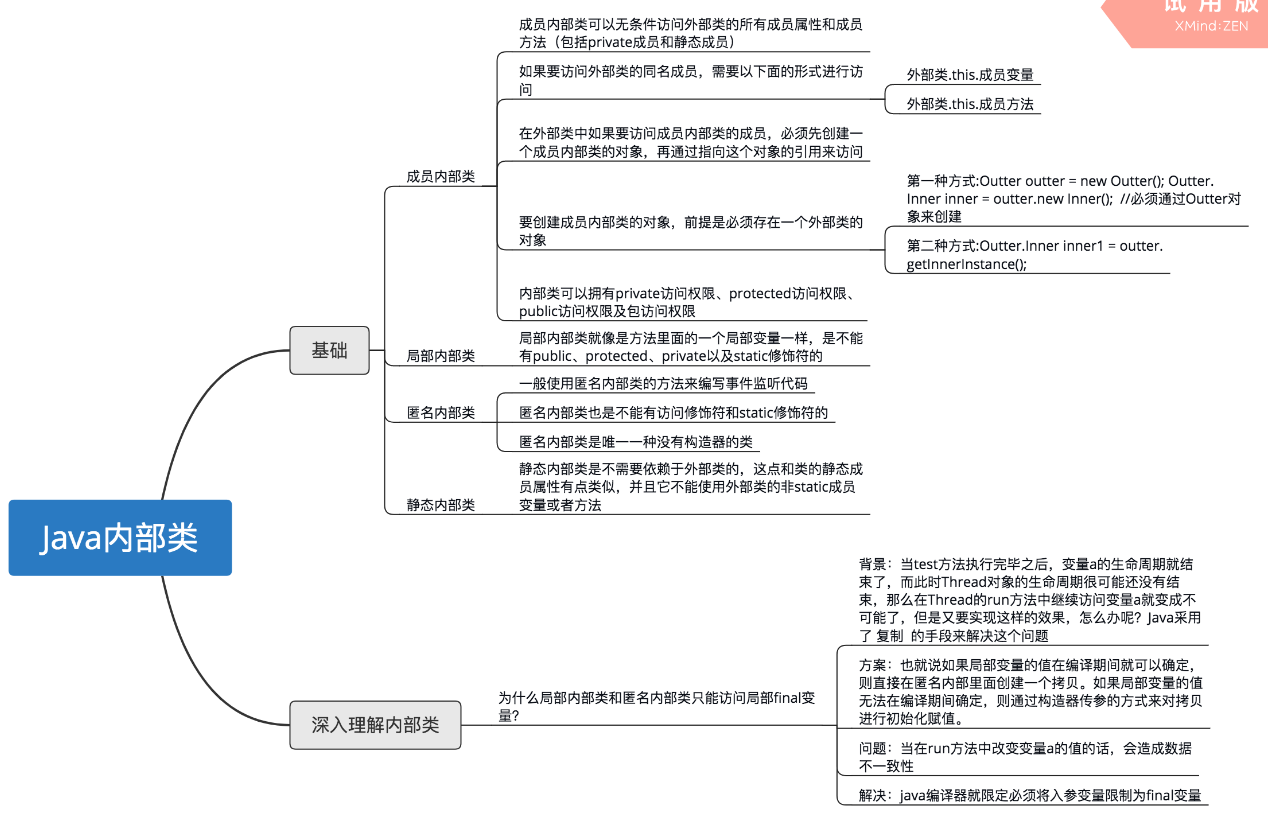
42、 instanceof 关键字作用:测试它左边的对象是否是它右边的类的实例,返回 boolean 的数据类型。
43、 Hashtable 线程安全,不支持key和value为空,key不能重复,但value可以重复,不支持key和value为null。 Hashmap 非线程安全,支持key和value为空,key不能重复,但value可以重复,支持key和value为null。
44、Java中接口只能使用public修饰,接口内方法默认为public abstract
45、子类A继承父类B,执行的先后顺序:父类B静态代码块->子类A静态代码块->父类B非静态代码块->父类B构造函数->子类A非静态代码块->子类A构造函数。
非静态代码块总是优先于构造函数执行。
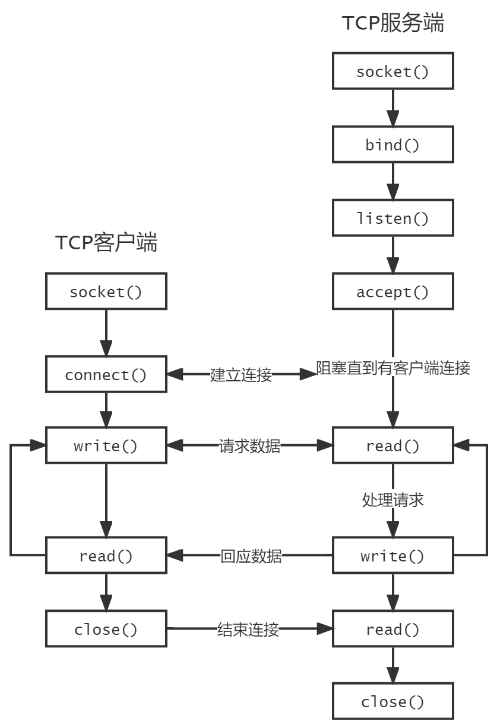
46、类A和类B在同一包中,类B有个protected的方法testB,类A不是类B的子类(或子类的子类),类A可以访问类B的方法testB
47、 final 定义的变量,可以在不是必须要在定义的同时完成初始化,也可以在构造方法中完成初始化。
48、面向对象方法的多态性是指对于同一个父类方法,不同的子类会有不同的实现方式。
49、switch语句后的控制表达式只能是short、char、int、long整数类型和枚举类型,不能是float,double和boolean类型。
50、intValue()是把Integer对象类型变成int的基础数据类型; parseInt()是把String 变成int的基础数据类型; Valueof()是把String转化成Integer对象类型。
51、类之间继承实现初始化的过程:
①初始化父类中的静态成员变量和静态代码块 ; ②初始化子类中的静态成员变量和静态代码块 ; ③初始化父类的普通成员变量和代码块**,再执行父类的构造方法;** ④初始化子类的普通成员变量和代码块**,再执行子类的构造方法;**
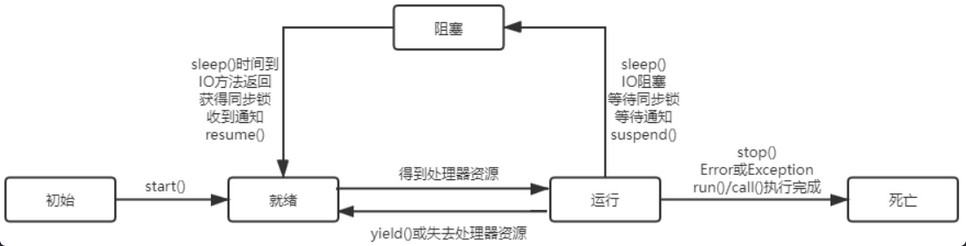
52、线程的生命周期中包含五种状态:初始态、就绪态、运行态、阻塞态、死亡状态。
其状态转换如下图所示:
53、use-a是依赖关系;has-a一般是聚合关系;is-a一般是继承关系。
54、任何字符与字符串相加都是字符串,但是是有顺序的,字符串前面的按原来的格式相加,字符串后面的都按字符串相加。
55、final修饰的方法不允许被子类覆盖;final修饰的成员变量为基本数据类型是,在赋值之后无法改变。当final修饰的成员变量为引用数据类型时,在赋值后其指向地址无法改变,但是对象内容还是可以改变的。 final修饰的成员变量在赋值时可以有三种方式。在声明时直接赋值;在构造器中赋值;在初始代码块中进行赋值。
56、在Java中,堆被划分成两个不同的区域:新生代 ( Young )、老年代 ( Old )。新生代 ( Young ) 又被划分为三个区域:Eden、From Survivor、To Survivor。
57、接口与抽象类
抽象类特点
抽象类中可以构造方法
抽象类中可以存在普通属性,方法,静态属性和方法。
抽象类中可以存在抽象方法。
如果一个类中有一个抽象方法,那么当前类一定是抽象类。
抽象类中的抽象方法,需要有子类实现,如果子类不实现,则子类也需要定义为抽象的。
接口的特点
在接口中只有常量,因为定义的变量,在编译的时候都会默认加上public static final
在接口中的方法,永远都被public来修饰。
接口中没有构造方法,也不能实例化接口的对象。
一个类可以实现多个接口。
一个类实现一个接口就必须实现其中所有的抽象方法,若该实现类不能实现接口中的所有方法则实现类定义为抽象类。
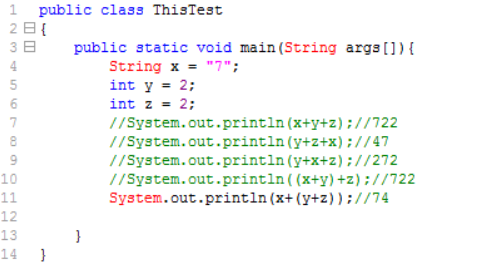
接口中定义的方法都需要有实现类来实现,如果实现类不能实现接口中的所有方法则实现类定义为抽象类。
在接口中只有方法的声明,没有方法体,jdk8之后可以有方法体。JDK1.8之后,接口里也可以有普通方法,包含默认方法(default methods)和静态方法(static methods),这些方法是可以有方法体的。
public interface MyInterface { // 默认方法 (default method)--普通方法。实现类可以选择继承默认实现或者覆盖它们。 default void defaultMethod() { System.out.println("这是一个默认方法"); } // 静态方法 (static method)--普通方法。只能被接口本身调用,而不能被实现类调用。 static void staticMethod() { System.out.println("这是一个静态方法"); } }
58、调用Base这个构造方法应该这样 new Base(a,b)。 在一个构造方法中调用另一个构造方法需要使用this关键字。
59、
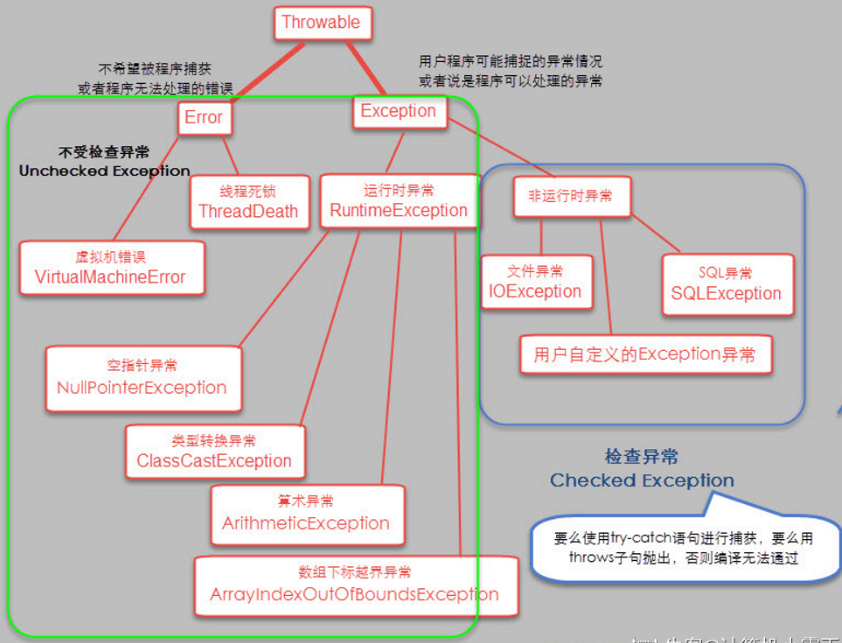
60、ThreadLocal存放的值是线程封闭,线程间互斥的,主要用于线程内共享一些数据,避免通过参数来传递; 从线程的角度看,每个线程都保持一个对其线程局部变量副本的隐式引用,只要线程是活动的并且 ThreadLocal 实例是可访问的;在线程消失之后,其线程局部实例的所有副本都会被垃圾回收; 在Thread类中有一个Map,用于存储每一个线程的变量的副本; 对于多线程资源共享的问题,同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式。
61、参数的顺序不同也算重载。
62、 创建线程对象有四种方式: 继承Thread类,重载run方法; 实现Runnable接口,实现run方法; 实现Callable接口,重载call方法; 使用线程池产生线程对象。
63、<<表示左移位
>>表示带符号右移位
>>>表示无符号右移
但是没有<<<运算符,Java中没有无符号左移
64、成员变量:编译和运行都参考左边; 成员函数(非静态):编译看左边,运行看右边; 静态函数:编译和运行都看左边。
65、给一个Integer赋予一个int类型的时候会调用Integer的静态方法valueOf。Integer的范围是-128~127,如果超出范围的话会新建一个对象,否则就是使用内存中的那个对象。
66、volatile单纯使用不能保证线程安全,他只是提供了一种弱的同步机制来确保修饰的变量的更新操作通知到其他线程; volatile关键字用在多线程同步中,可保证读取的可见性; JVM保证从主内存加载到线程工作内存的值是最新的; volatile能禁止进行指令重排序。
67、接口与抽象类区别
(1)抽象类不一定含有抽象方法,抽象类可以有非抽象方法,接口中的方法默认都是抽象方法 public abstract,JDK1.8之后,接口里也可以有普通方法,JDK1.9之后接口中可以定义私有方法; (2)抽象类中的方法是可以有方法体的。JDK1.8之后,接口中的普通方法,如默认方法(default methods)和静态方法(static methods),也可以有方法体,抽象类中可以有静态方法,接口中也可以有静态方法; (3)抽象类可以含有私有成员变量,接口不含有私有成员变量,接口中的成员变量都是public static final的,一般用作常量。抽象类和接口中都可以包含静态成员常量; (4)抽象类和方法都不能被实例化; (5)抽象类可以实现接口; (6)JDK1.8前,抽象类方法默认protected,JDK1.8时默认default; (7)抽象类可以有构造方法,接口中不能有构造方法; (8)一个类只能继承一个抽象类,但是可以实现多个接口,抽象类可以被抽象类继承,接口可以被接口实现; (9)在 Java 8 及之前的版本中,接口中不能定义实例变量或实例字段(即普通成员变量),只能定义常量(即静态 final 字段)和抽象方法。从 Java 9 开始,接口中可以定义私有方法、私有静态方法、私有常量和私有静态常量,这些成员是在接口的内部使用的,不能从接口的实现类中访问。 (10)抽象类可以不包含任何抽象方法,它可以包含普通方法、静态方法、成员变量、构造方法、初始化块以及其他非抽象成员。 (11)接口的默认访问权限是public。抽象类的访问权限与普通类的访问权限相同,默认是default(包级私有),当然也可以使用 public、protected、private。
interface MyInterface { //接口MyInterface访问权限是default
void foo(); //方法的访问权限默认是public
void bar(); //方法的访问权限默认是public
}
在上面的示例代码中,MyInterface 接口中的 foo() 和 bar() 方法没有指定访问修饰符,因此它们的访问权限默认为 public。而 MyInterface 接口本身没有指定访问修饰符,因此它的访问权限将是不加访问修饰符,也就是包级访问权限default。
(12) java接口的修饰符可以为:public、abstract、final、strictfp。public表示接口对所有类可见,可以在其他包中被访问,abstract表示该接口中至少有一个方法是抽象方法,final表示该接口不能被其他类所实现,strictfp表示接口中的浮点数运算使用严格的规则。https://worktile.com/kb/p/47546
68、Set 不能有重复的元素,且是无序的,要有空值也就只能有一个,因为它不允许重复。
List 可以有重复元素,且是有序的,要有空值也可以有多个,因为它可重复。
69、HashMap允许null值和null键。
70、Vector与ArrayList一样,也是通过数组实现的,不同的是Vector支持线程的同步。
71、关于Java程序初始化顺序:父类的静态代码块、子类的静态代码块、父类的普通代码块、父类的构造方法、子类的普通代码块、子类的构造方法。构造函数最后。
72、Thread的start和run方法,用start方法才能真正启动线程(多线程),此时线程会处于就绪状态,一旦得到时间片,则会调用线程的run方法进入运行状态。 而run方法只是普通方法,如果直接调用run方法,程序只会按照顺序执行主线程这一个线程。
73、try、catch、finally:try必须有,catch、finally有一个或都有。
执行try块、catch块时遇到了return或throw语句时,并不会结束该方法,而是去寻找该异常处理流程中是否包含finally块。
如果没有finally块,程序立即执行return或throw语句,方法终止;
如果有finally块,系统立即开始执行finally块,只有当finally块执行完成后,系统才会再次跳回来执行try块、catch块里的return或throw语句。
一句话:finally里的语句要比try和catch里的语句先执行,如果finally语句中有return语句,就不会再执行try和catch里的return和throw语句了。
finally一定会在return之前执行,但是如果finally使用了return或者throw语句,将会使trycatch中的return或者throw失效。
情况一:这种情况最简单,按顺序执行即可
/**
* 情况1:输出15
* @return
*/
public static int testtry01(){
int num = 5;
try {
num = num / 0;
} catch (Exception e) {
num = 10;
}finally {
num = 15;
}
return num;
}

情况二:出现了异常,try里的return来不及执行了,要先捕获异常执行catch中的语句,接着执行finally中的语句,最后try中的return就不在执行了
/**
* 情况2:输出15
* @return
*/
public static int testtry02(){
int num = 5;
try {
num = num / 0;
return num; //这里的return不执行
} catch (Exception e) {
num = 10;
}finally {
num = 15;
}
return num;
}
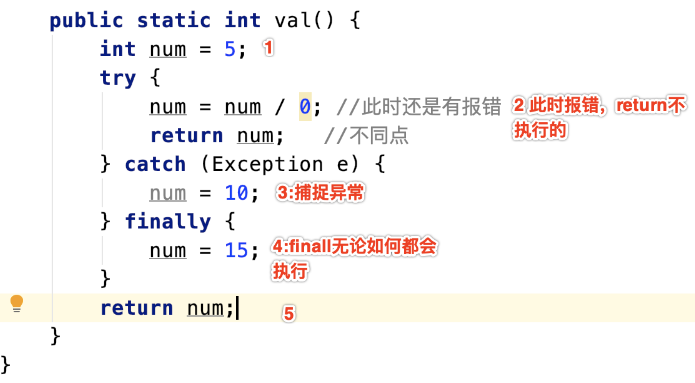
情况三:这种情况要特别注意,输出的是2而不是15
/**
* 情况3:输出2
* @return
*/
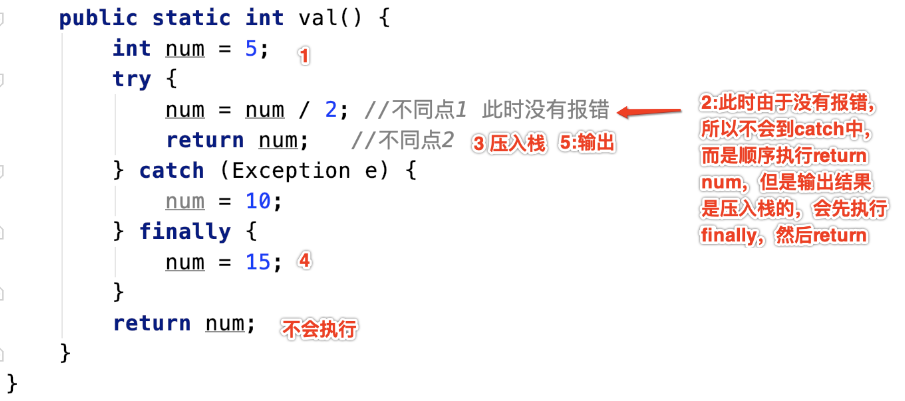
public static int testtry03(){
int num = 5;
try {
num = num / 2;
return num; //最后输出的是这里的值2
} catch (Exception e) {
num = 10;
}finally {
num = 15;
}
return num; //这里的return不执行
}
74、abstract 方法必须在abstract类或接口中
75、定义在同一个包(package)内的类可以不经过import而直接相互使用。
76、接口CallableStatement继承自PreparedSatement,接口PreparedStatement继承自Statement
77、Java中提供了两种用于多态的机制:通过子类对父类方法的覆盖实现多态(可理解为重写);利用重载来实现多态,即在同一个类中定义多个同名的不同方法来实现多态。
78、扩展类加载器(extensions class loader):它用来加载 Java 的扩展库; 系统类加载器(system class loader):它根据 Java 应用的类路径(CLASSPATH)来加载 Java 类; tomcat 为每个 App 创建一个 Loader,里面保存着此 WebApp 的 ClassLoader。需要加载 WebApp 下的类时,就取出 ClassLoader 来使用。
79、垃圾回收不能确定具体的回收时间
80、String split() 这个方法默认返回一个数组。
81、序列化是将数据转为n个byte序列的过程;反序列化是将n个byte转换为数据的过程。
82、类方法就是指类中用static 修饰的方法(非static 为实例方法),比如main 方法,那么可以以main 方法为例,可直接调用其他类方法,必须通过实例调用实例方法。
在类方法中不能有this关键字,直接调用类方法即可。在类方法中可以通过创建实例对象调用类的实例方法。
83、
String s1 = "coder";
String s2 = "coder";
String s3 = "coder" + s2;
String s4 = "coder" + "coder";
String s5 = s1 + s2;
System.out.println(s3 == s4); //false
System.out.println(s3 == s5); //false
System.out.println(s4 == "codercoder"); //true
s1,s2都是保存在字符串常量池中的对象;s3是新创建的对象,在堆中;s4,s5指向的也是字符串常量池中的对象;所以有s3!=s4,s3!=s5,s4=="codercoder"。即为false;false;true。
84、基本类型数组: byte[],short[],int[]默认值为0, boolean[]默认值为false float[],double[]默认值为0.0 对象类型数组默认值为null
85、start方法:用 start方法来启动线程,是真正实现了多线程, 通过调用Thread类的start()方法来启动一个线程,这时此线程处于就绪(可运行)状态,并没有运行,一旦得到cpu时间片,就开始执行run()方法。但要注意的是,此时无需等待run()方法执行完毕,即可继续执行下面的代码。所以run()方法并没有实现多线程。
run方法:run()方法只是类的一个普通方法而已,如果直接调用Run方法,程序中依然只有主线程这一个线程,其程序执行路径还是只有一条,还是要顺序执行,还是要等待run方法体执行完毕后才可继续执行下面的代码。
86、java运行时内存分为“线程共享”和“线程私有”两部分,方法区和java堆属于“线程共享”部分。
87、map集合的key都是无序不可重复的,HashMap中的key和value允许为null
88、Linux系统中关于进程与线程的描述:
进程是处于执行期的程序以及相关资源的总称; 内核调度的对象是线程,而不是进程; 线程被视为一个与其他进程共享某些资源的进程。
89、取模运算,结果的符号和被除数符号一致。被除数÷除数=商。
90、静态内部类不可以直接访问外围类的非静态数据,而非静态内部类可以直接访问外围类的数据,包括私有数据。
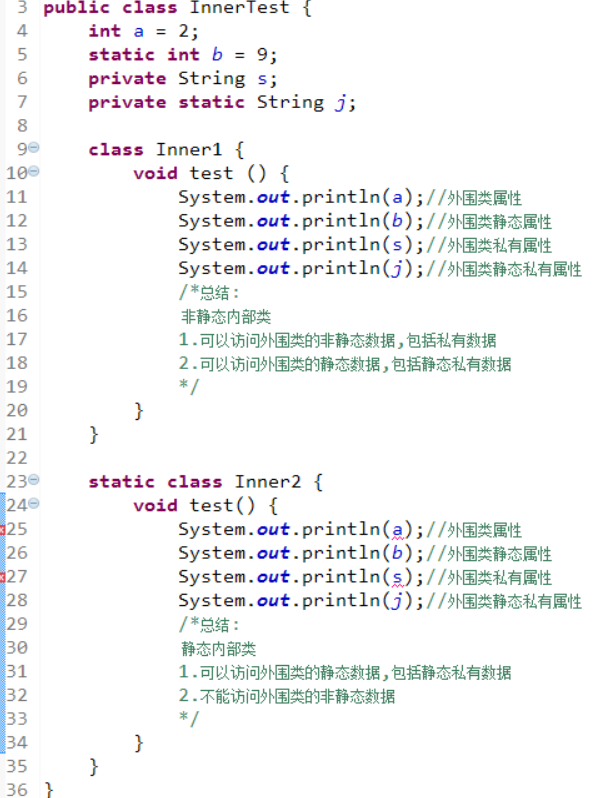
91、静态方法中不能调用对象的变量,因为静态方法在类加载时就初始化,对象变量需要在新建对象后才能使用。
92、类的final成员变量必须满足其中一个条件:在构造函数中赋值;初始化赋值。
93、JSP内置对象:
session对象:session对象指的是客户端与服务器的一次会话,从客户连到服务器的一个WebApplication开始,直到客户端与服务器断开连接为止; request对象:客户端的请求信息被封装在request对象中,通过它才能了解到客户的需求,然后做出响应; response对象:response对象包含了响应客户请求的有关信息; application对象:application对象是共享的,多个用户共享一个,以此实现数据共享和通信。
94、JavaWEB中HttpSessionAttributeListener类,当会话种绑定了属性或者删除了属性时,这个类会得到通知。
95、valitale关键字不能保证线程的安全性,因为它不具备原子性。
96、wait()、notify()、notifyAll()是Object类的方法。
97、switch语句可以接受String、 byte、 short、 int、 char、 Enum这几种类型
98、数组的默认值
在Java中,如果定义了一个数组但没有给数组的元素赋初值,那么数组的元素会根据它们的类型自动初始化为默认值。不同类型的数组元素的默认值也不同,具体如下:
- 整型数组的默认值为0。
- 浮点型数组的默认值为0.0。
- 字符型数组的默认值为'\u0000',即空字符。
- 布尔型数组的默认值为false。
- 引用类型数组的默认值为null。
例如,以下代码定义了一个长度为3的整型数组,但没有给数组的元素赋初值:
int[] numbers = new int[3];
在这种情况下,数组numbers的元素会被初始化为0,即numbers[0]、numbers[1]和numbers[2]的初始值都是0。
如果需要为数组的元素指定特定的初值,可以使用初始化列表来初始化数组。例如,以下代码定义了一个长度为5的整型数组,并为数组的元素指定了初值:
int[] numbers = {1, 2, 3, 4, 5};
在这种情况下,数组numbers的元素会被初始化为1、2、3 动初始化为默认值。例如,以下代码定义了一个长度为5的整型数组,并为前三个元素指定了初值:
int[] numbers = {1, 2, 3};
在这种情况下,数组numbers的前三个元素会被初始化为1、2和3,而数组的后两个元素会被自动初始化为0。
99、向上取整:Math.ceil(double a) 向下取整:Math.floor(double a) 四舍五入:Math.round(float a)和Math.round(double a),这两个方法分别用于对参数进行四舍五入,返回值类型为long。round()方法返回最接近参数的整数,如果参数为正数,则返回与参数最接近的整数;如果参数为负数,则返回与参数最接近的负整数。例如,Math.round(3.14)的结果为3,Math.round(-3.14)的结果为-3。
System.out.println(Math.ceil(-3.2)); // -3.0
System.out.println(Math.ceil(-3.5)); // -3.0
System.out.println(Math.ceil(-3.6)); // -3.0
System.out.println(Math.floor(-3.2)); // -4.0
System.out.println(Math.floor(-3.5)); // -4.0
System.out.println(Math.floor(-3.6)); // -4.0
100、Long.parseLong()用于将字符串转换为long类型的方法。
Long.parseLong()方法有两个参数,第一个参数是要解析的字符串,第二个参数是可选的进制(即字符串的基数)。如果不指定进制,则默认为10进制。例如,Long.parseLong("123")将返回值为123的long类型数值。
如果要将一个表示非10进制数的字符串解析为long类型的数值,则需要指定进制。例如,Long.parseLong("1010", 2)将返回值为10的long类型数值,因为它将字符串"1010"解析为2进制数。
101、如果没有显式地指定构造函数的访问修饰符,那么它将默认为public。
102、Integer.toBinaryString(num)和Integer.toString(num, 2)
// 将数字转换成字符串
Integer.toString(num);
// 将数字转换成二进制
Integer.toBinaryString(num);
// 将数字转换成八进制
Integer.toHexString(num);
// 将数字转换成十六进制
Integer.toOctalString(num);
Integer.toString(num,2) //将num转换为2进制
数组转二进制
ArrayList<Integer> list = new ArrayList();
if (num == 0) {
System.out.println(num);
} else {
while (num > 0) {
list.add(num % 2); //取余
num /= 2; //取整
}
ListIterator<Integer> it = list.listIterator(list.size()); //反向遍历一个整数类型的链表 list
while (it.hasPrevious()) { //判断是否还有前一个元素
System.out.print(it.previous()); //获取前一个元素,并打印输出
}
}
103、calendar.getActualMaximum(Calendar.DATE) 获取指定日期所在月份的最大天数。
104、map.keySet() 是 java.util.Map 接口中的一个方法,它返回一个 Set 集合,包含了当前 Map 对象中所有的键。
105、map.entrySet() 是 java.util.Map 接口中的一个方法,它返回一个 Set 集合,其中包含了 Map 中所有的键值对(即键和对应的值)。
106、compareTo() 方法是 java.lang.Comparable 接口中定义的一个方法,用于比较当前对象与另一个对象的大小关系。
如果一个类实现了 Comparable 接口,那么它必须实现 compareTo() 方法。compareTo() 方法的返回值为整型,表示当前对象与另一个对象的大小关系。如果当前对象小于另一个对象,则返回-1;如果当前对象等于另一个对象,则返回 0;如果当前对象大于另一个对象,则返回1。
107、java.util.Collections 是 Java 标准库中提供的一个工具类,它包含了一系列静态方法,用于操作集合和数组等数据结构。
以下是一些常用的 Collections 类方法:
sort(list):对列表进行排序,默认使用自然排序(即实现了Comparable接口的类的对象)。sort(list, comparator):对列表进行排序,使用指定的比较器进行排序。binarySearch(list, key):在排序后的列表中使用二分查找算法查找指定元素的索引位置。reverse(list):反转列表中元素的顺序。shuffle(list):随机打乱列表中元素的顺序。max(collection):返回集合中的最大元素。min(collection):返回集合中的最小元素。frequency(collection, obj):返回集合中某个元素出现的次数。replaceAll(list, oldVal, newVal):用新值替换列表中所有的旧值。
108、String.valueOf()
(1)String.valueOf(boolean b) : 将 boolean 变量 b 转换成字符串 (2)String.valueOf(char c) : 将 char 变量 c 转换成字符串 (3)String.valueOf(char[] data) : 将 char 数组 data 转换成字符串 (4)String.valueOf(char[] data, int offset, int count) : 将 char 数组 data 中 由 data[offset] 开始取 count 个元素 转换成字符串
(5)String.valueOf(double d) : 将 double 变量 d 转换成字符串 (6)String.valueOf(float f) : 将 float 变量 f 转换成字符串 (7)String.valueOf(int i) : 将 int 变量 i 转换成字符串 (8)String.valueOf(long l) : 将 long 变量 l 转换成字符串 (9)String.valueOf(Object obj) : 将 obj 对象转换成 字符串, 等于 obj.toString()
109、Applet 是一种在 Web 环境下,运行于客户端的Java程序组件。Applet运行之前,先调用 Init() 方法,然后调用 start() 方法,最后调用 paint() 方法。
110、java的基本编程单元是类,基本存储单元是变量。
111、接口中的方法默认是public abstract,子类的访问权限不能低于父类。
112、threadlocalmap使用开放定址法解决hash冲突,,而HashMap中使用的是链地址法。
113、>>是算术右移操作符,>>>是逻辑右移操作符。 >> 右移 高位补符号位,>>> 右移 高位补0。算数带符号,逻辑不带。
114、抽象方法规定没有方法体。
115、一般关系数据模型和对象数据模型之间有以下对应关系:表对应类,记录对应对象,表的字段对应类的属性。
116、wait() 导致当前的线程等待,直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法。
117、CyclicBarrier和CountDownLatch都可以让一组线程等待其他线程。前者是让一组线程相互等待到某一个状态再执行。后者是一个线程等待其他线程结束再执行。
118、Callable类的call()方法可以返回值和抛出异常。
119、定义在类中的变量是类的成员变量,可以不进行初始化,Java会自动进行初始化,如果是引用类型默认初始化为null,如果是基本类型例如int则会默认初始化为0 。 局部变量是定义在方法中的变量,必须要进行初始化,否则不同通过编译 。
120、接口和类都会产生.class
121、标准ASCII只使用7个bit,扩展的ASCII使用8个bit; 在简体中文的Windows系统中,ANSI就是GB2312; ASCII码是ANSI码的子集。
122、**默认的浮点数据类型是double,如果要指明使用float,则需要在后面加f,如:float f=11.1f **;long和double都占了64位(64bit)的存储空间。默认的整数是int。
123、普通类(外部类):只能用public、default(不写)、abstract、final修饰。 (成员)内部类:可理解为外部类的成员,所以修饰类成员的public、protected、default、private、static等关键字都能使用。 局部内部类:出现在方法里的类,不能用上述关键词来修饰。 匿名内部类:给的是直接实现,类名都没有,没有修饰符。
124、以下情况下的类要声明为抽象类:
一个类中有抽象方法则必须申明为抽象类; 当类是一个抽象类的子类,并且不能为任何抽象方法提供任何实现细节或方法体时; 当一个类实现一个接口,并且不能为任何抽象方法提供实现细节或方法体时。
125、复制的效率System.arraycopy>clone>Arrays.copyOf>for循环。
126、静态数据成员可以在类体内进行初始化。
127、并不是静态块最先初始化,而是静态域,静态域中包含静态变量、静态块和静态方法,其中需要初始化的是静态变量和静态块,而它们两个的初始化顺序是靠它们俩的位置决定的!
128、接口和抽象类
抽象类和方法都不能被实例化; 抽象类可以实现接口; jdk1.8前,抽象类方法默认protected,jdk1.8时默认default; 抽象类可以有构造方法,接口中不能有构造方法; 接口的默认访问权限是public。
129、 在使用匿名内部类的过程中,我们需要注意如下几点:
1、使用匿名内部类时,我们必须是继承一个类或者实现一个接口,但是两者不可兼得,同时也只能继承一个类或者实现一个接口。
2、匿名内部类中是不能定义构造函数的。
3、匿名内部类中不能存在任何的静态成员变量和静态方法。
4、匿名内部类为局部内部类,所以局部内部类的所有限制同样对匿名内部类生效。
5、匿名内部类不能是抽象的,它必须要实现继承的类或者实现的接口的所有抽象方法。
130、 +号两边如果有一边为字符类型 则为字符串连接。
131、被除数÷除数=商,取模运算mod,最终符号与除数符号相同;取余运算%,余数符号与被除数相同。
132、重写和重载
重写:两同两小一大 两同:方法名和参数列表相同
两小:返回值或声明异常比父类小(或相同)
一大:访问修饰符比父类的大(或相同)
重载:重载是在同一个类中,有多个方法名相同,参数列表不同(参数个数不同,参数类型不同、参数顺序不同),与方法的返回值无关,与权限修饰符无关。
133、 不会初始化子类的几种
- 调用的是父类的static方法或者字段
2.调用的是父类的final方法或者字段
- 通过数组来引用
134、数据类型转换由大到小需要强制转换,由小到大不需要。
135、Java只支持单继承,实现多重继承三种方式:(1)直接实现多个接口 (2)扩展(extends)一个类然后实现一个或多个接口 (3)通过内部类去继承其他类。
136、MVC只是将分管不同功能的逻辑代码进行了隔离,增强了可维护和可扩展性,增强代码复用性,因此可以减少代码重复。但是不保证减少代码量,多层次的调用模式还有可能增加代码量。 总结:一般来讲,使用设计模式都会增加代码量。
137、如果a.equals(b)返回true,那么a,b两个对象的hashcode必须相同。hashCode()相等的两个对象equal()不一定相等。
138、在接口里面的变量默认都是public static final 的,它们是公共的,静态的,最终的常量.相当于全局常量,可以直接省略修饰符。 实现类可以直接访问接口中的变量。
139、 "|"与"||"的区别
用法:condition 1 | condition 2、condition 1 || condition 2
"|"是按位或:先判断条件1,不管条件1是否可以决定结果(这里假设结果为true),都会执行条件2
"||"是逻辑或:先判断条件1,如果条件1可以决定结果(这里假设结果为true),那么就不会执行条件2
140、 wait():等待时线程别人可以用,释放锁了。sleep():等待时线程还是自己的,别人不能用,睡觉是抱着锁睡觉的。
141、final修饰变量,变量的引用(也就是指向的地址)不可变,但是引用的内容可以变(地址中的内容可变)。
142、重载要求方法的参数列表需要不一样(个数,或者参数类型),修改参数名或者修改返回值以及访问权限并没有用。
143、成员变量存放在堆区,方法中的局部变量存放在栈区。
144、JSON由{键:值}组成,需要注意的是: 1)键用引号(单双都行)引起来,也可以不使用引号; 2)值得取值类型:数字(整数或浮点数)、字符串(在双引号中)、逻辑值(true 或 false)、数组(在方括号中){"persons":[value1 , value2]}、JSON对象(在花括号中) {"address":{"province":"陕西"....}}、null
145、ThreadLocal继承Object,相当于没继承任何特殊的。 ThreadLocal没有实现任何接口。ThreadLocal并不是一个Thread,而是Thread的局部变量。ThreadLocal是采用哈希表的方式来为每个线程都提供一个变量的副本。ThreadLocal保证各个线程间数据安全,每个线程的数据不会被另外线程访问和破坏。
145、join()底层就是调用wait()方法的,wait()释放锁资源,故join也释放锁资源。
146、被static修饰的变量称为静态变量,静态变量属于整个类,而局部变量属于方法,只在该方法内有效,所以static不能修饰局部变量。
147、LinkedBlockingQueue是一个可选有界队列,不允许null值;PriorityQueue是一个无界队列,不允许null值,入队和出队的时间复杂度是O(log(n))。
148、Socket套接字:就是源Ip地址,目标IP地址,源端口号和目标端口号的组合。
服务器端:ServerSocket提供的实例,ServerSocket server= new ServerSocket(端口号)
客户端:Socket提供的实例,Scket soc=new Socket(ip地址,端口号)
149、正则表达式:
^:起始符号,^x表示以x开头
$:结束符号,x$表示以x结尾
[n-m]:表示从n到m的数字
\d:表示数字,等同于[0-9]
X{m}:表示由m个X字符构成,\d{4}表示4位数字
150、CallableStatement接口继承自PreparedSatement接口,PreparedStatement接口继承自Statement接口
151、floor: 求小于参数的最大整数。返回double类型,例如:Math.floor(-4.2) = -5.0; ceil: 求大于参数的最小整数。返回double类型,例如:Math.ceil(5.6) = 6.0; round: 对小数进行四舍五入后的结果。返回int类型,例如:Math.round(-4.6) = -5。
151、Java中二维数组的定义,一维长度必须定义,二维可以后续定义。
152、parseInt得到的是基础数据类型int,valueof得到的是装箱数据类型Integer,valueInt得到的是基础数据类型int
153、创建socket连接:Socket s = new Socket(“192.168.1.1”,8080)
服务器端:ServerSocket提供的实例 ServerSocket server = new ServerSocket(端口号) 客户端:Socket提供的实例 Socket client = new Socket(IP地址,端口号)
154、父类静态方法不能被子类重写,而是被隐藏。
155、Java中单例模式的6种实现方式: 懒汉式(线程不安全) 饿汉式(线程安全) 懒汉式(线程安全) 双重检查锁实现(线程安全) 静态内部类实现(线程安全) 枚举类实现(线程安全)
156、在定义静态常量时,可以使用两种方式:static final int i=234; 和 final static int i=234;
通常建议使用static final int i=234;的方式,因为这种方式更符合Java编码习惯。在Java中,习惯将static关键字放在前面,表示这是一个静态变量;而将final关键字放在后面,表示这是一个常量。
156、final修饰引用类型变量,final只保证这个引用的地址不变,即一直引用同一对象。但这个对象可以改变。 final修饰基本数据类型变量不能被改变。
157、反射 getDeclaredField:查找该Class所有声明属性(静态/非静态),但是他不会去找实现的接口/父类的属性; getField:只查找该类public类型的属性,如果找不到则往上找他的接口、父类,依次往上,直到找到或者已经没有接口/父类,就是只查找public; get方法是获得user对象下前面指定好的属性的值,而获取static属性时get()括号里的对象可以写成null。
通过以下方法可反射获取到User对象中static属性的值:
(1) User. class. getDeclaredField ("name"). get (null);
(2) User. class. getField ("name"). get (null);
(3) User user=new User(); return user. getClass(). getField ("name").get (user);
(4) User user=new User(): return user. getClass(). getDeclaredField ("name"). get (user);
158、计算余弦值使用Math类的cos()方法; toRadians()是将角度转换为弧度; toDegrees()是将弧度转换为角度。
159、类的修饰符
外部类只能是public,可以没有public; 成员内部类前面可以修饰public,protected和private; 局部内部类不可以加上 static 和 public,protected,private 等, 可以带上 final
外部类前可以修饰:public、default、abstract、final
成员内部类前可以修饰:public、protected、default、private、abstract、final、static
局部内部类前可以修饰:abstract、final
匿名内部类:不能有访问修饰符和static修饰符的,匿名内部类是唯一一种没有构造器的类
内部静态类:不能使用外部类的非static成员变量或者方法
其中:访问修饰符(public、protected、default、private),其他都是非访问修饰符
// public
class ClassD {// ClassD 为外部类,可以没有 public , 且只能带上 public, 不可以使用 protected,private 等其他
// public, protected
private static final class E {// E 为成员内部类, 可以加上 public,protected,private, 等和 static final
}
public static void main(String[] args) {
class G {// 局部内部类
}
}
public void test() {
final class H {// 局部内部类 , 不可以加上 static 和 public,protected,private 等, 可以带上 final
}
}
}
public class Example {
public void exampleMethod() {
Runnable runnable = new Runnable() { //匿名内部类
public void run() {
System.out.println("Runnable running");
}
};
new Thread(runnable).start();
}
}
160、子类可以继承父类所有的成员,不可以继承父类的构造方法,只可以调用父类的构造方法。对private这样的,没有访问权。构造器、静态初始化块、实例初始化块不继承。 子类继承了父类的私有方法的(不管是否是final),只是直接调用父类的私有方法是不可以的,但是利用反射的方式可以调用。
161、super和this都只能位于构造器的第一行,而且不能同时使用,这是因为会造成初始化两次。this用于调用重载的构造器,super用于调用父类被子类重写的方法。
162、程序计数器是一个比较小的内存区域,用于指示当前线程所执行的字节码执行 到了第几行,是线程隔离的; 原则上讲,所有的对象都是在堆区上分配内存,是线程之间共享的; Java方法执行内存模型,用于存储局部变量,操作数栈,动态链接,方法出口等信息,是线程隔离的; 方法区,又叫静态区,跟堆一样,被所有的线程共享,用于存储已经被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
163、int与Integer、new Integer()进行==比较时,结果永远为true;
Integer与new Integer()进行==比较时,结果永远为false;
Integer与Integer进行==比较时,看范围,在大于等于-128小于等于127的范围内为true,在此范围外为false。
164、
public void test() {
int a = 10;
System.out.println(a++ + a--); //输出21
}
a++ 先把10赋值给a 再+1,所以左边是10,但此时a=11。右边a--也是先赋值 a=11,再-1。10+11=21 此时a=10。
165、抛InterruptedException的代表方法有: java.lang.Object 类的 wait 方法; java.lang.Thread 类的 sleep 方法; java.lang.Thread 类的 join 方法。
166、Servlet 生命周期:加载--->实例化--->服务--->销毁
167、Java基本数据类型转换:byte、short、char—>int—>long—>float—>double 由低精度到到精度可以自动转换,而高精度到低精度会损失精度。
168、5 >> 2 相当于 5除于2的平方,等于1 ,>>> 表示无符号 右移,高位用0 填充,0001 右移两位 0000
169、switch(x)语句中,x可以是下列类型的数据:
jdk1.7之前byte,short ,int ,char
jdk1.7之后加入String
java8,switch支持10种类型
基本类型:byte char short int
包装类 :Byte,Short,Character,Integer String enum
实际只支持int类型 Java实际只能支持int类型的switch语句,那其他的类型时如何支持的
a、基本类型byte char short 原因:这些基本数字类型可自动向上转为int, 实际还是用的int。
b、基本类型包装类Byte,Short,Character,Integer 原因:java的自动拆箱机制 可看这些对象自动转为基本类型
c、String 类型 原因:实际switch比较的string.hashCode值,它是一个int类型
d、enum类型 原因 :实际比较的是enum的ordinal值(表示枚举值的顺序),它也是一个int类型 所以也可以说 switch语句只支持int类型
170、关于子类如何调用父类中的方法:
子类构造函数调用父类构造函数用super; 子类重写父类方法后,若想调用父类中被重写的方法,用super; 未被重写的方法可以直接调用。
171、final和static
https://blog.csdn.net/gao_zhennan/article/details/72892946
final:
final实例字段必须在构造对象时初始化。也就是说,必须在构造器执行完成之前,将字段赋予初值,否则将不能再修改这个字段;
每创建一个实例,就会为实例变量分配一次内存;
当引用为基本数据类型,则该引用的值在实例后不可以再改变;当修饰对象时,则该对象地址不可以再指向另一个对象,但是引用的对象的内容可以改变;
当final修饰方法时,则该方法将不可以被重写,不过该方法任然可以继承给子类;
final修饰类,则该类不可以被继承。
static:
- static关键字修饰的字段与方法都会随着类的加载而分配和加载进内存,而非静态字段与方法只用在实例化对象时才会分配内存。并且 static关键字修饰的字段与方法都只加载一次,类加载后就会存在,是优先于对象的存在;而非静态的每实例化一次对象都会加载一次;
- 被
static修饰的方法是属于类的方法,不是属于实例的方法,因此不能被重写; - static关键字修饰的字段可以修改值;
- static修饰方法,则该方法不可以访问非静态变量,只可以访问静态成员;
- 对于静态字段与静态方法,虽然可以使用对象来访问它们,这也是合法的,但是它们是属于类的,建议使用类名来方法这些字段与方法;
- 静态变量只能在类主体中定义,不能在方法中定义。
172、线程的生命周期中包含五种状态:初始态、就绪态、运行态、阻塞态、死亡状态。其状态转换如下图所示:
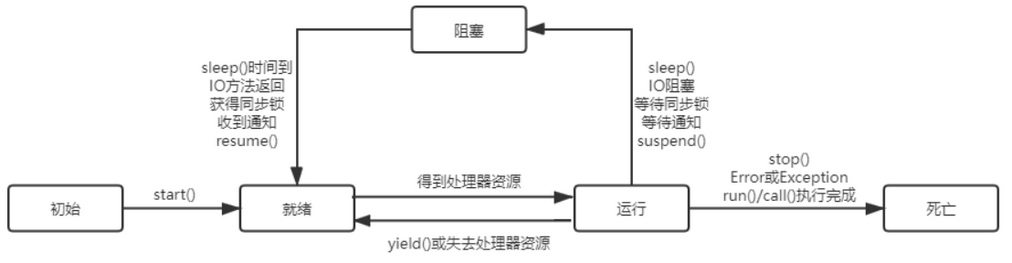
173、yield():释放锁,同优先级的其他线程有机会获得锁。
174、
175、父类静态代码块、子类静态代码块、父类代码块、父类构造方法、子类代码块、子类构造方法
class A {
public A() {
System.out.println("class A");
}
{
System.out.println("I'm A class");
}
static {
System.out.println("class A static");
}
}
public class B extends A {
public B() { //构造方法
System.out.println("class B");
}
{ //代码块
System.out.println("I'm B class");
}
static { //静态代码块
System.out.println("class B static");
}
public static void main(String[] args) {
new B();
}
}
//输出
//class A static
//class B static
//I'm A class
//class A
//I'm B class
//class B
176、
String s1 = "coder";
String s2 = "coder";
String s3 = "coder" + s2;
String s4 = "coder" + "coder";
String s5 = s1 + s2;
System.out.println(s3 == s4); //false
System.out.println(s3 == s5); //false
System.out.println(s4 == "codercoder"); //true
s1,s2都是保存在字符串常量池中的对象;s3是新创建的对象,在堆中;s4,s5指向的也是字符串常量池中的对象;所以有s3!=s4,s3!=s5,s4=="codercoder"。即为false;false;true。
177、sleep()、wait()、yield()、join()
Java 中的 sleep()、wait()、yield() 和 join() 都是用于多线程编程的方法,它们的作用和使用场景有所不同。
**(1)sleep():不释放锁 **
sleep() 方法是线程类 Thread 中的一个静态方法,用于让当前线程暂停执行一段时间。它的作用是让当前线程进入阻塞状态,等待一段时间后再继续执行。sleep() 方法的语法为:
public static void sleep(long millis) throws InterruptedException
其中,millis 参数表示需要暂停的时间,单位为毫秒。sleep() 方法会抛出 InterruptedException 异常,如果在睡眠期间被其他线程中断,就会抛出该异常。
sleep() 方法常用于模拟耗时操作,或者在多线程程序中控制线程的执行顺序。
(2)wait():释放锁
wait() 方法是 Object 类中的一个方法,用于让当前线程等待另一个线程发出的通知。它的作用是让当前线程进入阻塞状态,等待另一个线程调用 notify()、notifyAll() 或者等待超时后再继续执行。wait() 方法的语法为:
public final void wait() throws InterruptedException
public final void wait(long timeout) throws InterruptedException
public final void wait(long timeout, int nanos) throws InterruptedException
其中,第一个参数是等待的时间,单位为毫秒。如果不传入参数,就会一直等待,直到被其他线程中断或者收到通知。如果传入参数,就会等待指定的时间,如果在等待期间没有收到通知,就会自动唤醒。wait() 方法也会抛出 InterruptedException 异常,如果在等待期间被其他线程中断,就会抛出该异常。
wait() 方法常用于多线程之间的协作,例如线程 A 在执行某个任务时需要等待线程 B 完成某个操作后才能继续执行。
(3)yield():不释放锁
yield() 方法是线程类 Thread 中的一个静态方法,用于让当前线程让出 CPU 的使用权,让其他线程有机会运行。它的作用是让当前运行的线程进入就绪状态,让 CPU 调度器重新选择执行哪个线程。yield() 方法的语法为:
public static void yield()
yield() 方法没有参数,调用它会让当前线程让出 CPU,让其他线程有机会运行。但是,由于线程调度是由 JVM 控制的,因此 yield() 方法并不能保证让其他线程立即运行。
yield() 方法常用于调试多线程程序时,可以通过让线程让出 CPU 使得线程运行的顺序更加随机,更容易暴露线程安全问题。
(4)join():释放锁
join() 方法是线程类 Thread 中的一个方法,用于让当前线程等待另一个线程执行完毕后再继续执行。它的作用是让当前线程进入阻塞状态,等待另一个线程执行完毕后再继续执行。join() 方法的语法为:
public final void join() throws InterruptedException
public final void join(long millis) throws InterruptedException
public final void join(long millis, int nanos) throws InterruptedException
其中,第一个参数是等待的时间,单位为毫秒。如果不传入参数,就会一直等待,直到被其他线程中断或者被等待线程执行完毕。如果传入参数,就会等待指定的时间,如果在等待期间被等待线程执行完毕,就会自动唤醒。join() 方法也会抛出 InterruptedException 异常,如果在等待期间被其他线程中断,就会抛出该异常。
join() 方法常用于多线程之间的协作,例如在主线程中启动多个子线程,并希望等待所有子线程执行完毕后再继续执行主线程的任务。可以通过调用每个子线程的 join() 方法,让主线程等待每个子线程执行完毕后再继续执行。
178、Statement对象用于执行不带参数的简单SQL语句; Prepared Statement 对象用于执行预编译SQL语句; Callable Statement对象用于执行对存储过程的调用; 创建Statement是不传参的,PreparedStatement是需要传入sql语句。
179、父类new直接执行构造方法;子类new,先执行父类的构造方法,再执行自己的构造方法。
180、静态变量只能在类主体中定义,不能在方法中定义。
181、 Arraylist默认数组大小是10,扩容后的大小是扩容前的1.5倍,最大值小于Integer 的最大值减8,如果新创建的集合有带初始值,默认就是传入的大小,超过默认值会进行扩容。
ArrayList 的最大容量是 Integer.MAX_VALUE - 8,其中 Integer.MAX_VALUE 表示 int 类型的最大值,也就是 2^31 - 1。而 -8 是因为 ArrayList 内部需要使用一些额外的空间来存储一些元数据,例如数组长度等信息,因此需要保留一些空间。如果超过了这个容量,再进行扩容就会导致数组大小超过 Integer 的最大值,从而抛出 OutOfMemoryError 异常。
182、进程与线程
一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程(通常说的主线程); 资源分配给进程,同一进程的所有线程共享该进程的所有资源; 多进程里,子进程可获得父进程的所有堆和栈的数据,而线程会与同进程的其他线程共享数据,拥有自己的栈空间; 线程的通信速度更快,切换更快,因为他们在同一地址空间内; 线程之间共享进程获得的数据资源,所以开销小,但不利于资源的管理和保护;而进程执行开销大,但是能够很好的进行资源管理和保护。
183、new,序列化对象,反射,克隆分别创建一个对象的方法,只有new和反射用到了构造方法。
184、java回收算法:复制算法和标记清理算法:
复制算法:两个区域A和B,初始对象在A,继续存活的对象被转移到B。此为新生代最常用的算法; 标记清理:一块区域,标记可达对象(可达性分析),然后回收不可达对象,会出现碎片,那么引出标记-整理算法;
标记-整理算法:多了碎片整理,整理出更大的内存放更大的对象。
185、
String a = new String("myString");
String b = "myString";
String c = "my" + "String";
String d = c;
System.out.println(a == b); //false
System.out.println(a == c); //false
System.out.println(b == c); //true
System.out.println(b == d); //true
186、
byte b1=1,b2=2,b3,b6,b8;
final byte b4=4,b5=6,b7;
b3=(b1+b2); /*语句1*/
b6=b4+b5; /*语句2*/
b8=(b1+b4); /*语句3*/
b7=(b2+b5); /*语句4*/
语句1 :(b1 + b2)被转换为int类型,但是b3仍为byte,所以出错,要么将b3转化为int 要么将(b1+ b2)强制转换为byte类型。所以语句1错误。
语句2:b4 、b5被声明final所以类型是不会转换,计算结果任然是byte,所以语句2正确。
语句3:(b1 + b4) 结果仍然转换成int,所以语句3错误。
语句4: (b2 + b5) 结果仍然转换为int,所以语句4错误。
187、为了更好地组织类,Java提供了包机制。包是类的容器,用于分隔类名空间。如果没有指定包名,所有的示例都属于一个默认的无名包。Java中的包一般均包含相关的类,java是跨平台的,所以java中的包和操作系统没有任何关系,java的包是用来组织文件的一种虚拟文件系统。
import语句并没有将对应的java源文件拷贝到此处仅仅是引入,告诉编译器有使用外部文件,编译的时候要去读取这个外部文件。
定义在同一个包(package)内的类可以不经过import而直接相互使用。
188、ServletConfig接口默认是GenericServlet实现的。
189、方法区在JVM中也是一个非常重要的区域,它与堆一样,是被线程共享的区域。 在方法区中,存储了每个类的信息(包括类的名称、方法信息、字段信息)、静态变量、常量以及编译器编译后的代码等。
190、反射:
通过反射可以动态的实现一个接口,形成一个新的类,并可以用这个类创建对象,调用对象方法; 通过反射,可以突破Java语言提供的对象成员、类成员的保护机制,访问一般方式不能访问的成员; Java的反射机制会给内存带来额外的开销。例如对永生堆的要求比不通过反射要求的更多
191、静态块:用static修饰的代码块,JVM加载类时执行,仅执行一次; 构造块:类中直接用大括号{}定义的代码块,每一次创建对象时执行,且同时具有构造块和构造函数时,构造块先于构造函数运行 ;
public class B
{
public static B t1 = new B();
public static B t2 = new B();
{
System.out.println("构造块"); //这个是构造块
}
static
{
System.out.println("静态块");
}
public static void main(String[] args)
{
B t = new B();
}
}
//输出:构造块 构造块 静态块 构造块
192、在抽象类中,抽象方法没有实现,即没有花括号:
public abstract void doSomething();
这个方法没有方法体,只有方法签名。子类必须实现这个方法,否则子类也必须被声明为抽象类。普通的方法必须有方法体,并且不能被声明为抽象方法。
193、final的的成员方法只能读取类的成员变量,这里的类的成员变量包括了两部分:类变量和实例变量。另外,fianl修饰的方法不能被重写(覆盖) 。
194、is-a,理解为是一个,代表继承关系。 如果A is-a B,那么B就是A的父类。 like-a,理解为像一个,代表组合关系。 如果A like a B,那么B就是A的接口。
has-a,理解为有一个,代表从属关系。 如果A has a B,那么B就是A的组成部分。 USES-A:依赖关系,A类会用到B类,这种关系具有偶然性,临时性。但B类的变化会影响A类。这种在代码中的体现为:A类方法中的参数包含了B类。
195、String split 这个方法默认返回一个数组,如果没有找到分隔符,会把整个字符串当成一个长度为1的字符串数组返回到结果,所以此处结果就是1
String str = "";
System.out.print(str.split(",").length); //输出1
196、while() 中表达式的判断,在C语言中大于0的int值都会被认为是true,而java中没有这个机制,必须是boolean类型的。
197、
byte b = 1;
char c = 1;
short s = 1;
int i = 1;
// 三目,一边为byte另一边为char,结果为int
// 其它情况结果为两边中范围大的。适用包装类型
i = true ? b : c; // int
b = true ? b : b; // byte
s = true ? b : s; // short
// 表达式,两边为byte,short,char,结果为int型
// 其它情况结果为两边中范围大的。适用包装类型
i = b + c; // int
i = b + b; // int
i = b + s; // int
// 当 a 为基本数据类型时,a += b,相当于 a = (a) (a + b)
// 当 a 为包装类型时, a += b 就是 a = a + b
b += s; // 没问题
c += i; // 没问题
// 常量任君搞,long以上不能越
b = (char) 1 + (short) 1 + (int) 1; // 没问题
// i = (long) 1 // 错误
198、子类构造方法在调用时必须先调用父类的,由于父类没有无参构造,必须在子类中显式调用,在子类的有参构造函数中添加:super(参数)。
199、子类引用父类的静态字段,只会触发子类的加载、父类的初始化,不会导致子类初始化。
public class P {
public static int abc = 123;
static{
System.out.println("P is init");
}
}
public class S extends P {
static{
System.out.println("S is init"); //子类引用父类的静态字段,只会触发子类的加载、父类的初始化,不会导致子类初始化
}
}
public class Test {
public static void main(String[] args) {
System.out.println(S.abc);
}
}
//输出:P is init<br />123
200、同步普通方法锁的是this也就是当前对象,同步静态方法锁的是类对象,也就是Class对象。
202、值类型变量的作用域主要是在栈上分配内存空间内。在Java中,值类型变量包括基本数据类型和枚举类型。
203、通过阅读源码可以知道,string与stringbuffer都是通过字符数组实现的。 其中string的字符数组是final修饰的,所以字符数组不可以修改。 stringbuffer的字符数组没有final修饰,所以字符数组可以修改。 string与stringbuffer都是final修饰,只是限制他们所存储的引用地址不可修改。至于地址所指内容能不能修改,则需要看字符数组可不可以修改。
204、ResultSet中记录行的第一列索引为1。
205、

1. 只看尖括号里边的!!明确点和范围两个概念
2.如果尖括号里的是一个类,那么尖括号里的就是一个点,比如List<A>,List<B>,List<Object>
3. 如果尖括号里面带有问号,那么代表一个范围,<? extends A>代表小于等于A的范围,<? super A>代表大于等于A的范围,<?>代表全部范围
4. 尖括号里的所有点之间互相赋值都是错,除非是俩相同的点
5. 尖括号小范围赋值给大范围,对,大范围赋值给小范围,错。如果某点包含在某个范围里,那么可以赋值,否则,不能赋值
6. List<?>和List 是相等的,都代表最大范围
7.补充:List既是点也是范围,当表示范围时,表示最大范围
public static void main(String[] args) {
List<A> a;
List list;
list = a; //A对,因为List就是List<?>,代表最大的范围,A只是其中的一个点,肯定被包含在内
List<B> b;
a = b; //B错,点之间不能相互赋值
List<?> qm;
List<Object> o;
qm = o; //C对,List<?>代表最大的范围,List<Object>只是一个点,肯定被包含在内
List<D> d;
List<? extends B> downB;
downB = d; //D对,List<? extends B>代表小于等于B的范围,List<D>是一个点,在其中
List<?extends A> downA;
a = downA; //E错,范围不能赋值给点
a = o; //F错,List<Object>只是一个点
downA = downB; //G对,小于等于A的范围包含小于等于B的范围,因为B本来就比A小,B是A的子类
}
206、
下面的代码定义了两个类A和B,其中类B继承自类A。类A中定义了一个无参构造方法,当创建类A的实例时,会输出"A"。类B中定义了一个无参构造方法,并在该方法中调用了父类A的无参构造方法super()。当创建类B的实例时,会先调用父类A的构造方法输出"A",然后再输出"B"。
为什么会输出A
在类B的构造方法中,我们调用了父类A的构造方法super()。如果一个类没有显式地指定调用父类的哪个构造方法,Java会默认调用父类的无参构造方法。在这个例子中,由于类A中定义了无参构造方法,所以在创建类B的实例时,会先调用父类A的无参构造方法输出"A",然后再执行类B的构造方法输出"B"。
可是B类中没有写super()啊
在Java中,如果一个子类的构造方法没有显式地调用父类的构造方法,Java会默认在子类的构造方法中加入一条隐式的调用语句super(),用来调用父类的无参构造方法。因此,在类B的构造方法中虽然没有显式地写出super(),但实际上它会默认调用父类A的无参构造方法。这也是在创建类B的实例时,为什么会先输出"A",然后再输出"B"的原因。
class A{
public A(){
System.out.println("A");
}
}
class B extends A{
public B(){
System.out.println("B");
}
public static void main(String[]args){
B b=new B();
}
}
//输出
A
B
207、下面的代码中第1处出现了错误,name没有初始化
interface IDemo {
public static final String name; //--1
void print(); //--2
public void getInfo(); //--3
}
abstract class Person implements IDemo{ //4
public void print(){}
}
修改代码为正确的
public static final String name = "demo"; // 初始化常量name
可以这样初试化吗
public static final String name;
name = "null";
不可以,正确的做法是在声明变量的同时进行初始化。
为什么类Person没有实现IDemo的全部方法
在Java中,一个类实现一个接口时,必须实现接口中所有的抽象方法,否则该类必须被声明为抽象类。这里的类Person已经被定义为抽象类了,所以可以不实现接口IDemo的全部方法。
208、Math.random()随机生成区间[0,1)的浮点数
乘以100,区间[0-100) 取[1-100],则加1,得[1,101)
所以生成1-100的随机数为:
(int)Math.random()*100+1; //[0,100)=>[1,101)
或
Math.ceil(Math.random()*99)+1 //[0,99)+1=>ceil [0,99]=>[1,100]
或
Math.ceil(Math.random()*99+1) //[0,99)+1=>[1,100)=>ceil [1,100]
209、在 "12" == "12" 中,并不会将字符串转为整数进行比较,而是直接比较两个字符串对象的引用地址是否相同,这个比较的结果是true。
210、大--->小,要进行强制转换;小--->大,不需要强制转换。
char c =74; //实际上是字母 J
double d = 34.4;
long l = 4990;
int i = 4L; //改为:long i = 4L或int i = (int)4L
float f = 1.1; //改为:float f = 1.1f或double f = 1.1;
String str = String("bb"); //改为:String str = new String("bb")或String str = "bb";
int k = new String("aa"); //改为:String k = new String("aa")

想要将字符串转为int型,需要使用int n = Integer.parseInt(str),要求str是整数字符串。
二、框架
1、PROPAGATION_SUPPORTS支持当前事务,如果当前没有事务,则以非事务方式执行; PROPAGATION_MANDATORY传播行为使用当前的事务,如果当前没有事务,则抛出异常; PROPAGATION_REQUIRES_NEW新建事务,如果当前存在事务,则把当前事务挂起。
2、@Transactional可以作用在类上,代表这个类的所有公共非静态方法都将启用事务; 可以通过@Transactional的propagation属性,指定事务的传播行为; 可以通过@Transactional的isolation属性,指定事务的隔离级别; 可以通过@Transactional的rollbackFor属性,指定发生哪些异常时回滚。
3、Spring AOP支持的通知类型包括前置通知、后置通知、环绕通知、返回通知、异常通知。
4、Spring对事务隔离级别提供了支持,并通过枚举类型Propagation定义了7种事务隔离级别,Propagation成员: REQUIRED:若当前存在事务,就沿用当前事务,否则就新建一个事务来运行此方法。 REQUIRED_NEW:无论当前是否存在事务,都要新建一个事务来运行此方法。 SUPPORTS:若当前存在事务,就沿用当前事务,否则就采用无事务的方式运行此方法。 NESTED表示,若当前存在事务,则采用嵌套事务执行此方法,否则就创建新事务来执行此方法。
5、@ComponentScan注解用于定义Bean的扫描策略。 @ComponentScan注解默认规则是对当前包及其子包中的Bean进行扫描。 @ComponentScan注解的basePackages属性用于自定义要扫描哪些包。 @ComponentScan注解只是定义了扫描范围,在此范围内带有特定注解的Bean才会被载入容器。
6、Spring MVC拦截器包含三个方法:preHandle()、postHandle()、afterCompletion()。
7、Spring容器中Bean包含五种作用域:singleton、prototype、request、session、globalSession。
8、在Spring MVC中实现上传功能,主要依赖MultipartHttpServletRequest从读取请求中的文件,然后对读取到的MultipartFile类型进行处理。
9、@AutoWired注解还可以写在set方法、构造器上;@Qualifier注解用于声明Bean的名称,可以引用默认名称;@Bean注解可以用于装配任何Bean。
10、在Spring MVC中,可以通过URL携带参数。例如,"/user/{id}" 是为某Controller中某方法声明的访问路径,其中“{id}”代表这一级携带的是id参数。可以注解@PathVariable提取id参数。
11、Spring AOP的实现方式:
JDK动态代理,是Java提供的动态代理技术,可以在运行时创建接口的代理实例。Spring AOP默认采用这种方式,在接口的代理实例中织入代码。
CGLib动态代理,采用底层的字节码技术,在运行时创建子类代理的实例。当目标对象不存在接口时,Spring AOP就会采用这种方式,在子类实例中织入代码。
12、当发现有多种类型的Bean时,@Primary注解会通知IoC容器优先使用它所标注的Bean进行注入;@Quelifier注解可以与@AutoWired注解组合使用,达到通过类型和名称一起筛选Bean的效果。
13、Spring Boot中aop和ioc是指什么
AOP(面向切面编程):通过在运行时动态地将代码切入到类的某个特定方法、特定位置执行,实现功能的复用和解耦。AOP 的核心思想是将业务逻辑和横切关注点分离开来,通过切面(Aspect)来实现横切关注点的代码复用,是OOP(面向对象编程)的一种延续。
IOC(控制反转):控制反转实际上就是当你想要创建对象的时候不自己去创建, 而是向Spring IOC容器发起请求, 告诉他我要创建哪个哪个对象了, 然后Spring IOC容器就会返回一个对象实例给你, 这就是IOC控制反转,将创建对象的权利交由Spring IOC容器管理。
依赖注入是IOC控制反转的具体实现,是实现用于解决依赖性设计模式。因为对象资源的获取全部要依赖于Spring IOC容器, 组件之间的依赖关系由容器在应用系统运行期来决定, 在需要的时候由Spring IOC容器动态地往组件中注入需要的实例对象,就叫依赖注入。
14、Spring Boot中有哪些常用注解,含义是什么
- @SpringBootApplication:标记 Spring Boot 应用的主类,同时包含了 @Configuration、@EnableAutoConfiguration 和 @ComponentScan 注解。
- @RestController:用于标记一个类,表示这个类的所有方法都返回 JSON 数据,相当于 @Controller 和 @ResponseBody 的组合。
- @RequestMapping:用于映射请求 URL 到 Controller 中的某个方法。
- @Autowired:用于自动注入一个 Bean 对象,Spring Boot 会自动在容器中查找类型匹配的 Bean 对象进行注入。
- @Value:用于注入配置文件中的属性值,可以指定默认值和占位符,例如:@Value("${server.port:8080}")。
- @ConfigurationProperties:用于将配置文件中的属性值注入到一个 Bean 对象中,可以指定前缀和忽略未知属性,例如:@ConfigurationProperties(prefix = "app.config", ignoreUnknownFields = true)。
- @EnableAutoConfiguration:用于开启自动配置,Spring Boot 会根据 classpath 下的 jar 包和配置文件进行自动配置,大大简化了配置过程。
- @ComponentScan:用于扫描指定的包和类,自动注册 Bean 对象到 Spring 容器中。
- @Transactional:用于声明事务,可以标记在类或方法上,表示这个类或方法需要进行事务管理。
15、BeanFactory是所有Spring Bean的容器根接口; FactoryBean是一种创建Bean的方式。
16、在Spring MVC中实现上传功能,主要依赖MultipartHttpServletRequest从读取请求中的文件,然后对读取到的MultipartFile类型进行处理。
17、Spring AOP: 连接点(join point),对应的是具体被拦截的对象,因为Spring只支持方法,所以被拦截的对象往往就是指特定的方法,AOP将通过动态代理技术把它织入对应的流程中; 切点(point cut),有时候,我们的切面不单单应用于单个方法,也可能是多个类的不同方法,这时,可以通过正则式和指示器的规则去定义,从而适配连接点。切点就是提供这样一个功能的概念; 通知(advice),就是按照约定的流程下的方法,分为前置通知、后置通知、环绕通知、事后返回通知和异常通知,它会根据约定织入流程中; 切面(aspect),是一个可以定义切点、各类通知和引入的内容,SpringAOP将通过它的信息来增强Bean的功能或者将对应的方法织入流程。
18、可以管理Spring Bean的生命周期的注解有:@PostContruct、@PreDestroy。
19、ioc面向对象,aop面向切面。
20、在Spring MVC中,Model、ModelMap、ModelAndView都可以作为数据模型对象,以上述类型作为控制器的方法参数时,Spring MVC会自动实例化这些类型。ModelAttribute是注解,用于定义控制器方法执行之前,对数据模型的操作。
三、Redis
1、list保证数据线性有序且元素可重复,它支持lpush、blpush、rpop、brpop等操作,可以当作简单的消息队列使用,一个list最多可以存储2^32-1个元素
2、Redis除支持string(字符串)、hash(哈希)、list(列表)、set(集合)及zset(有序集合)五种数据类型外,还支持geospatial、hyperloglog、bitmapden等数据类型。
3、Redis的主从复制
Redis 通过主从复制机制可以实现读写分离; Redis 的主从复制机制无法实现自动故障转移; 数据的复制是单向的,只可以由主节点到从节点; 一个从节点只能有一个主节点。
4、string数据类型:string的Value最多可以容纳的数据长度是512M;string是二进制安全的;string中setnx命令只有在key不存在时才能设置值;string中incr命令可以对不存在的key操作。
5、set中的数据具有唯一性,list中的数据不具有唯一性;set中的数据无序;list中的数据有序;
6、BGSAVE每次运行都要执行fork操作创建子进程,这属于重量级操作,不宜频繁执行,因此,RBD没法做到实时的持久化。
7、Redis 中主从复制机制的操作:可以通过配置文件、启动命令、客户端命令三种方式开启主从复制;主从复制的开启是在从节点发起;slaveof no one命令可以用于断开主从复制关系;从节点断开主从复制关系后,不会删除已有的数据,只是不再接受主节点新的数据变化。
8、Redis中事务和MySQL中事务的区别:
Redis不支持事务回滚,MySQL支持事务回滚。 Redis以Multi事务的开始,以Exec执行事务的commands队列;MySQL以Begin开启一个事务,以Commit提交事务。 Redis实现事务基于commands队列; MySQL实现事务基于undo/redo日志。 Redis默认不开启事务;MySQL默认开启事务。
9、Redis 中RDB 与AOF两种持久化机制的比较:
对业务数据敏感的应用场景选用AOF持久化机制;追求大数据集恢复速度的应用场景选用RDB持久化机制;AOF持久化机制比RDB持久化机制的存储速度快;AOF持久化机制比RDB持久化机制的恢复速度慢。
10、Redis 6.0版本的新功能:
Redis 6.0版本提供了ACL功能,支持更细粒度的权限控制; Redis 6.0版本的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程; Redis 6.0版本在兼容 RESP2 的基础上支持 RESP3; Redis 6.0改进了命令行的超时选项。
11、Redis的zset数据类型:
Redis 使用ziplist(压缩列表)来实现zset类型时需要满足zset类型元素个数小于zset-max-ziplist-entries; Redis 使用ziplist(压缩列表)来实现zset类型时需要满足zset类型所有member的长度小于zset-max-ziplist-value; zset通过用户额外提供一个评分(score)的参数来为集合中的成员进行排序,并且是插入有序; zset数据类型中成员是唯一不可重复的,但评分不是。
12、Redis常用命令
https://blog.csdn.net/weixin_55076626/article/details/126504134
字符串string操作命令
SET key value 设置指定的key值
GET key 获取指定key的值
SETEX key seconds value 设置指定key的值,并将key的过期时间设为seconds秒
SETNX key value 只有在key不存在时设置key的值
哈希hash操作命令
HSET key field value 将哈希表key中的字段field的值设为value
HGET key field 获取存储在哈希表中指定字段的值
HDEL key field 删除存储在哈希表中的指定字段
HKEYS key 获取哈希表中所有字段
HVALS key 获取哈希表中所有值
HGETALL key 获取在哈希表中指定key的所有字段和值
列表list操作命令
LPUSH key value1 [value2] 将一个或多个值插入到列表头部
LRANGE key start stop 获取列表指定范围内的元素
RPOP key 移除并获取列表最后一个元素
LLEN key 获取列表长度
BRPOP key1 [key2] timeout 移出并获取列表的最后一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止
集合set操作命令
SADD key member1 [member2] 向集合添加一个或多个成员
SMEMBERS key 返回集合中的所有成员
SCARD key 获取集合中的成员数
SINTER key1 [key2] 返回给定所有集合的交集
SUNION key1 [key2] 返回所有给定集合的并集
SDIFF key1 [key2] 返回给定所有集合的差集
SREM key member1 [member2] 移除集合中一个或多个成员
有序集合sorted set操作命令
ZADD key score1 member1 [score2 member2] 向有序集合添加一个或多个成员,或者更新已存在成员的分数
ZRANGE key start stop [WITHSCORES] 通过索引区间返回有序集合中指定区间内的成员
ZINCRBY key increment member 有序集合中对指定成员的分数加上增量increment
ZREM key member [member...] 移除有序集合中的一个或多个成员
13、Redis的持久化:
RDB是以快照的形式,将内存中的数据整体拷贝到硬盘上。 执行RDB存储时会产生阻塞,因此RDB不适合实时备份,而适合定时备份。 AOF操作的实时性好,但是产生的数据体积大,数据的恢复速度慢。 AOF持久化方式是将redis的操作日志以追加的方式写入磁盘文件中。与RDB持久化相比,AOF的实时性较好。
14、Redis中geospatial数据类型:
geopos用于获取当前定位; georadiusmember用于找出位于指定元素范围内的其他元素; geohash用于返回一个或多个位置元素的geohash表示; georadius用于以给定的经纬度为中心,找出某一半径内的元素。
15、Redis 中主从复制机制的作用:
实现数据的热备份; 当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复; 分担服务器负载,提高服务器的并发量;
实现主节点的自动故障转移是哨兵模式的作用。
16、Redis中zset数据类型与list数据类型的比较:
zset与list中的数据都是有序的; zset相较于list更耗内存; zset相较于list访问中间元素更快; zset的底层数据结构是散列表和跳跃表,list的底层数据结构是链表。
17、Redis 中内存统计相关指标:
通过 info memory可以查看内存使用情况; used_memory_rss代表的含义是Redis进程占据操作系统的内存; used_memory中不包含内存碎片; mem_allocator是Redis使用的内存分配器,默认是jemalloc。
18、Redis集群中的消息类型:
新节点收到MEET消息后会回复一个PONG消息; 接收者收到PING消息后会回复一个PONG消息; 故障恢复后新的主节点会广播PONG消息; 节点收到PUBLISH命令后,会先执行该命令,然后向集群广播这一消息。
19、Redis中list数据类型的操作指令:
rpoplpush <key1> <key2>指令表示从<key1>列表右边吐出一个值插入到 <key2>列表左边; lrange mylist 0 -1可以取到mylist中的所有值; 执行lpop/rpop <key>取完列表中所有值后,列表移除; linsert <key> before <value> <newvalue>的返回值是新的列表长度。
20、Redis中的SDS(简单动态字符串):
SDS在C字符串的基础上加入了free和len字段; SDS可以存取二进制数据; 由于SDS记录了长度,可以杜绝缓冲区溢出;
21、Redis 中集群的作用:
实现故障的自动转移; 提高响应能力; 突破了单机内存大小限制。
22、Redis的事务保证了一致性和隔离性,但并不保证原子性和持久性。
23、在Multi组队阶段出现某个命令错误,则执行时整个队列都会取消,在执行阶段某个命令错误,则执行时错误命令不执行,其他命令顺利执行。
24、Redis中set数据类型的操作指令:
sismember <key> <value>用于判断成员元素是否是集合的成员; 执行smembers <key>命令可以取出该集合的所有值; 执行spop <key>将从集合中随机吐出一个值; sunion <key1> <key2> 返回两个集合的并集元素。
25、Redis中的list数据类型:
list数据类型具有单键多值的特点; list数据类型底层是双向链表; list数据类型数据有序; list数据类型数据支持索引下标操作,只是性能较差。
26、当Redis以“includes”的方式引入其他配置文件时,如果同一个配置项在不同配置文件中都有定义,那么以最后面的配置项为准。
27、Redis中的hash数据类型:
hkeys <key>命令用于获取hash集合中所有的field; hvals <key>命令用于获取该hash集合中所有的value; hincrby <key> <field> <increment>命令用于为指定key对应的field增加指定值; hsetnx <key> <field> <value>命令用于在field不存在时将其值设置为value。
28、Redis中的哨兵功能:
客户端在通过哨兵获得主节点信息后,会直接建立到主节点的连接,后续的请求会直接发向主节点; 哨兵节点本质上是redis节点; 在哨兵节点启动和故障转移阶段,各个节点的配置文件会被重写; 哨兵节点在故障转移完成后,会将新的主节点信息发送给客户端,以便客户端及时切换主节点。
29、Redis中的操作命令:
keys * 查看当前库中所有key; flushdb 清空当前数据库中的所有 key; exists key 判断key是否存在; unlink key 非阻塞删除指定的key。
30、redis默认的持久化机制是RDB; RDB持久化机制是以快照形式存储数据结果,存储格式简单; AOF持久化机制是以日志形式存储操作过程,存储格式复杂; 持久化的目的是防止数据的意外丢失,确保数据安全性。
31、开启AOF需要在配置文件中配置appendonly yes; AOF缓存区的同步文件策略由参数appendfsync控制; 开启RDB文件压缩需要在配置文件中配置rdbcompression yes; 根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定自动触发条件。
32、Redis中string数据类型的数据结构:
string采用预分配冗余空间的方式来减少内存的频繁分配; string的数据类型是简单动态字符串(simple Dynamic string); string的内部结构实现上类似Java的ArrayList; string扩容机制如下:当字符串长度小于 1M 时,扩容都是加倍现有的空间;如果超过 1M,扩容时一次只会多扩 1M 的空间,需要注意的是字符串最大长度为 512M。
33、Redis 中哨兵的功能:
哨兵会不断得检查主节点和从节点是否正常工作; 当主节点不能正常工作时,哨兵实现主节点的自动故障转移; 哨兵可以将故障转移的结果发送给客户端; 34、MongoDB将数据存放在内存,当内存不够时,只将热点数据放入内存,其他数据存在磁盘;Redis将数据全部存在内存, 当内存不够时,可以选择指定的LRU算法删除数据。
35、zset底层的存储结构包括ziplist或skiplist,在同时满足有序集合保存的元素数量小于128个和有序集合保存的所有元素的长度小于64字节的时候使用ziplist,其他时候使用skiplist。
36、集群的节点通信机制:
普通端口用于为客户端提供服务以及节点间数据迁移; 集群端口的端口号是普通端口的端口号+10000(10000是固定值,无法改变); 在集群中,没有数据节点与非数据节点之分,并且集群中的每个节点,都提供了两个TCP端口; 集群端口只用于节点之间的通信,不要使用集群端口连接客户端。
四、Linux
1、chown(change owner)命令用于设置文件所有者和文件关联组的命令; chmod(change mode)命令是控制用户对文件的权限的命令; cd(change directory)命令用于切换当前工作目录; chgrp(change group)命令用于变更文件或目录的所属群组。
2、useradd 命令用于建立用户帐号; usermod 命令用于修改用户帐号; groupadd 命令用于创建一个新的工作组,新工作组的信息将被添加到系统文件中; userdel 命令用于删除用户帐号。
3、 > 表示输出重定向,例如:
echo "123" > test.txt
表示将 123 输入到文件 test.txt 中
>> 输出重定向追加,例如:
echo "123" >> test.txt
表示将 123 追加到文件 test.txt 中
4、 : 表示切换到命令模式,以在最底一行输入命令; q(quit)表示退出 vi; w(write)表示保存文件; ! 表示强制,例如 q! 表示强制退出不保存,w! 表示强制保存。
5、chmod 命令是控制用户对文件的权限的命令; more 命令类似 cat,不过会以一页一页的形式显示,更方便使用者逐页阅读; cp(copy file)命令主要用于复制文件或目录; touch 命令用于修改文件或者目录的时间属性,包括存取时间和更改时间。若文件不存在,系统会建立一个新的文件。
6、文件类型和文件权限由10个字符组成: 第 1 位表示文件的类型; 第 2 - 4 位表示文件所有者对文件的权限; 第 5 - 7 位表示文件所有者所在组的用户对文件的权限; 第 8 - 10 位表示其他用户对文件的权限。
用二进制表示 rwx,r 代表可读,w 代表可写,x 代表可执行,- 表示没有权限。 如果可读,权限二进制为 100,十进制是4; 如果可写,权限二进制为 010,十进制是2; 如果可执行,权限二进制为 001,十进制是1;
Linux下权限对应的数字为:r =4, w =2, x =1,所以,6就是rw- ,4就是r--,5就是r-x 。
u:主用户,g:同组用户,o:其他用户,a(ugo):所有用户。 权限设定:+增加权限,- 取消权限,= 唯一设定权限。
7、find 命令用于查找文件: . 在当前目录查找 -name 指定文件名,.log 表示后缀名为 .log, 是通配符,表示匹配任意字符串 -mtime 指定修改时间(以天为单位),+xx 表示修改时间大于 xx 天, -xx 表示修改时间小于 xx 天 -type 是指定文件类型,b 表示块设备文件,d 表示目录,c 表示字符设备文件,p 表示管道文件,l 表示符号链接文件,f 表示普通文件 -size 指定文件大小,+xx 表示文件大小大于 xx,-xx 表示文件大小小于 xx
xargs 把前一命令输入当作后一命令输出,通常配合管道使用。
8、在RHEL5系统中使用vi编辑文件report.txt时,要自下而上查找字符串“2006”,应该在命令模式下使用 ?2006
从上往下查找,就像坐滑滑梯-------/ 从下往上查找,就需要倒挂金钩了-------?
9、孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。 僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。 孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
10、linux 创建文件的命令
(1)touch[tʌtʃ]: touch命令用于创建空文件或修改现有文件的时间戳(timestamp),如果指定的文件不存在,则会创建一个新文件。例如,要创建一个名为"file.txt"的空文件,可以使用以下命令:
touch file.txt
(2)echo:echo命令用于向终端输出文本,并可以将输出的文本重定向到文件中,从而创建一个新文件。例如,要创建一个名为"file.txt"的文件,内容为"Hello, world!",可以使用以下命令:
echo "Hello, world!" > file.txt
(3)cat:cat命令用于将文件的内容输出到终端,也可以将多个文件的内容合并到一个文件中。如果指定的文件不存在,则会创建一个新文件。例如,要创建一个名为"file.txt"的文件,内容为"Hello, world!",可以使用以下命令:
cat > file.txt
Hello, world!
Ctrl + D
在执行完上述命令后,会等待用户输入内容,输入完成后按下Ctrl + D组合键即可保存并退出。
(4)vi/vim:vi和vim是Linux中常用的文本编辑器,可以用于创建或修改文件。例如,要创建一个名为"file.txt"的文件,可以使用以下命令:
vi file.txt
然后,在vi编辑器中输入文本,输入完成后按下Esc键,然后输入":wq"保存并退出。
11、Linux ls(list files)命令用于显示指定工作目录下之内容(列出目前工作目录所含之文件及子目录); Linux cd(change directory)命令用于切换当前工作目录; Linux ln(link files)命令是一个非常重要命令,它的功能是为某一个文件在另外一个位置建立一个同步的链接; Linux more 命令类似 cat ,不过会以一页一页的形式显示,更方便使用者逐页阅读。
12、grep 命令用于查找文件里符合条件的字符串。从文件内容查找匹配指定字符串的行:
grep "被查找的字符串" 文件名
grep "牛客" 文件名 | wc -l
| 为管道符,前面命令的标准输出作为后面命令的标准输入; wc 命令用于计算字数,-l 表示显示行数。
13、把 f1.txt 复制到 f2.txt 可以使用如下命令:
cat f1.txt > f2.txt
cp f1.txt f2.txt
14、/bin,bin 是 Binaries(二进制文件)的缩写,这个目录存放着最经常使用的命令。 /etc,etc 是 Etcetera(等等)的缩写,这个目录用来存放所有的系统管理所需要的配置文件和子目录; /dev,dev 是 Device(设备)的缩写,该目录下存放的是 Linux 的外部设备,在 Linux 中访问设备的方式和访问文件的方式是相同的; /lib,lib 是 Library(库) 的缩写这个目录里存放着系统最基本的动态连接共享库,其作用类似于 Windows 里的 DLL 文件。几乎所有的应用程序都需要用到这些共享库。
15、大写的PWD代表环境变量,小写的pwd是shell命令输出当前工作目录,查看系统中所有环境变量可以使用env,可以看到PWD的值会随着工作目录变化而变化。
16、vi 编辑器里面如何删除最后一行:先输入G,再输入 dd。
17、www 80 ,ftp 20 ,21,书上一般写ftp端口21,对应两种模式,应该是主动20,被动模式20。
18、uniq 命令用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用。sort 命令用于将文本文件内容加以排序。uniq 只能处理相邻的重复行,所以需要先排序才能去重。
19、使用 vi 编辑某文件时
ndd: 删除当前行开始的连续 n 行; dd:删除光 标所在行; n1,n2d:删除 n1 到 n2 行,例如 1,10d 表示删除 1 到 10 行; n,$d:删除从 n 行开始至文本末尾,例如 8,$d 表示删除第 8 行至末尾 。
20、locate并不真正对硬盘上的文件系统进行查找,而是对文件名数据库进行检索,而且可以使用通配符?和* find命令从指定的起始目录开始,递归地搜索其各个子目录,查找满足寻找条件的文件并对之采取相关的操作 whereis命令只能用于程序名的搜索,而且只搜索二进制文件(参数-b)、man说明文件(参数-m)和源代码文件(参数-s) type命令用来显示指定命令的类型,判断给出的指令是内部指令还是外部指令
21、server-name:通知DHCP客户服务器名称; fixed-address:分配给客户端一个固定的地址; filename:开始启动文件的名称,应用于无盘工作站; hardware:指定网卡接口类型和MAC地址。
22、httpd.conf:网络服务器软件的配置文件,对WWW服务器进行访问、控制存取和运行等控制 。 lilo.conf:由引导管理程序 lilo 读取的文件。 inetd.conf:保存了系统提供internet服务的数据库并对其进行控制,如打开/关闭某项服务。 resolv.conf:域名解析器使用的配置文件。
23、ls(list files)命令用于显示指定工作目录下之内容(列出目前工作目录所含之文件及子目录); df(disk free) 命令用于显示目前在 Linux 系统上的文件系统磁盘使用情况统计; ps(process status)命令用于显示当前进程的状态,类似于 windows 的任务管理器; top 命令用于实时显示 process 的动态。
24、关机命令有halt init 0 poweroff shutdown -h 时间,其中shutdown是最安全的。 重启命令有reboot, init 6, shutdow -r 时间。
25、/etc/passwd是记录用户信息的文件 /etc/shadows是记录用户组信息的文件 /etc/group是记录用户密码的文件,密码是经过md5加密的字符串 /etc/gshadow是记录用户组相关信息的加密文件
26、
$0 脚本启动名(包括路径)
$n 第n个参数,n=1,2,…9
$* 所有参数列表(不包括脚本本身)
$@ 所有参数列表(独立字符串)
$# 参数个数(不包括脚本本身)
$$ 当前程式的PID
$! 执行上一个指令的PID
$? 执行上一个指令的返回值
27、du(disk usage)命令用于显示目录或文件的大小,du 会显示指定的目录或文件所占用的磁盘空间。 df(disk free)命令用于显示目前在 Linux 系统上的文件系统磁盘使用情况统计。
28、在Linux系统下,你用vi编辑器对文本文件test.txt进行了修改,想保存对该文件所做的修改并正常退出vi编辑器,可以:在命令模式下执行ZZ命令;在末行模式下执行:wq。
29、 cat:由第一行开始显示文件所有内容; tac:从最后一行开始显示文件的所有内容,注意 tac 与cat 写法正好相反; more:一页一页的显示文件内容,只能向后翻页; less:也是一页一页显示文件内容,但是可以通过键盘上的【pagedown】,【pageup】控制向后,向前翻页; head:显示一个文件的前几行; tail:显示一个文件的后几行;
30、基本的linux操作系统:ext文件系统,ext2文件系统; 日志文件系统:ext3文件系统,ext4文件系统,Reiser文件系统,JFS文件系统,XFS文件系统; 写时复制文件系统:ZFS文件系统,Btrf文件系统
31、Linux进程通信方式:
1,管道及有名管道
2,信号(signal)
3, 报文队列(消息队列)
4,共享内存
5,信号量(semaphore)
6,套接字(socket)
7,文件锁。文件锁不能直接用于进程间通信,但是它可以作为一种辅助机制,用于实现一些进程间通信的需求。
32、将文件file1复制为file2可以用下面的命令:
(1)cp file1 file2 # 常用
(2)cat file1 >file2 # 常用
(3)cat < file1 >file2
(4)dd if=file1 of=file2
(5)cat file1 | cat >file2
33、route 命令用于显示和操作IP路由表; tracert 为 Windows 路由跟踪实用程序,可以用于确定 IP 数据包访问目标时所选择的路径; ping 命令用于检测主机; netstat 命令用于显示网络状态,利用 netstat 指令可以得知整个 Linux 系统的网络情况。
34、linux下查看当前网络连接的命令:netstat
35、使用vi命令是: dd 删除光标所在的那一整行 ; yy 复制光标所在的那一整行; p 将已复制的数据在光标的下一行粘贴; P 将已复制的数据在光标的上一行粘贴。
36、
linux中shell变量$#,$@,$0,$1,$2的含义解释:
变量说明:
$$
Shell本身的PID(ProcessID)
$!
Shell最后运行的后台Process的PID
$?
最后运行的命令的结束代码(返回值)
$-
使用Set命令设定的Flag一览
$*
所有参数列表。如"$*"用「"」括起来的情况、以"$1 $2 … $n"的形式输出所有参数。
$@
所有参数列表。如"$@"用「"」括起来的情况、以"$1" "$2" … "$n" 的形式输出所有参数。
$#
添加到Shell的参数个数
$0
Shell本身的文件名
$1~$n
添加到Shell的各参数值。$1是第1参数、$2是第2参数…
37、Linux程序运行后,文件句柄0,1,2分别是标准输入,标准输出,标准错误。
38、 链接操作实际上是给系统中已有的某个文件指定另外一个可用于访问它的名称。 软连接可以跨文件系统,硬连接不可以 ; 软连接可以对一个不存在的文件名进行连接 ; 软连接可以对目录进行连接。
39、解压或压缩操作: -c 建立压缩文件 ; -v 压缩的过程显示文件 ; -f 使用档名; -z 是否具有gzip属性
-x:extract files from an archive 即从归档文件中释放文件; -v:verbosely list files processed 即详细列出要处理的文件; -z:filter the archive through gzip 即通过gzip解压文件; -f:use archive file or device ARCHIVE 即使用档案文件或设备; 通常情况下解压 .tar.gz 和 .tgz 等格式的归档文件就可以直接使用 tar xvzf; 因为要解压到指定目录下,所以还应在待解压文件名后加上 -C(change to directory)参数。
# 将当前目录下的归档文件 myftp.tgz 解压缩到 /tmp 目录下
tar xvzf myftp.tgz -C /tmp
解压命令:
tar命令:用于解压.tar文件,命令格式为:tar -xvf file.tar
gzip命令:用于解压.gz文件,命令格式为:gzip -d file.gz
bzip2命令:用于解压.bz2文件,命令格式为:bzip2 -d file.bz2
unzip命令:用于解压.zip文件,命令格式为:unzip file.zip
压缩命令:
tar命令:用于打包和压缩文件,命令格式为:tar -cvf file.tar file1 file2 ...
gzip命令:用于压缩文件,命令格式为:gzip file
bzip2命令:用于压缩文件,命令格式为:bzip2 file
zip命令:用于打包和压缩文件,命令格式为:zip file.zip file1 file2
tar是操作.tar的命令;
gzip是压缩.gz压缩包的命令;
compress:压缩.Z文件;
uncompress:解压缩.Z文件
40、option routers 192.168.0.1; 配置默认网关; option subnet-mask 255.255.255.0; 配置子网掩码; option domain-name-servers 192.168.1.1; 指定DNS服务器; option domain-name-servers; 配置多个DNS服务器。
41、Linux启动流程: 1,BIOS加电自检(或采取UEFI作为启动的第一步); 2,从硬盘0柱面 0磁道 第一扇区读512字节的MBR主引导记录; 3,运行引导程序Grub并根据其配置加载kernel镜像后初始化; 4,根据/etc/inittab中系统初始化配置执行/etc/rc.sysinit脚本; 5,根据第3步读到的runlevel值启动对应服务; 6,运行/etc/rc.local; 7,生成终端待用户登录。
42、可用来查看Linux主机的默认路由的命令:直接route命令就可以显示默认路由,netstat命令需要加一个参数-route
43、如果想列出当前目录以及子目录下所有扩展名为“.txt”的文件,可以使用命令:find -name "*.txt"
44、内核分为进程管理系统 、内存管理系统 、I/O管理系统 和文件管理系统等四个子系统。
45、文件描述符0:标准输入设备; 文件描述符1:标准输出设备; 文件描述符2:标准错误输出设备。
46、使用Vim编辑器: dd:删除当前行(0:返回行首) ndd:删除光标行往下n行(含光标行)内容 dgg:删除光标当前行及以上内容 dG:删除光标当前行及以下内容 dH:删除当前页面第1行至光标行 p:粘贴到光标下一行 u:撤销一次操作 Ctrl + r:反撤销(一次)
47、使用fork函数得到的子进程从父进程的继承了整个进程的地址空间,包括:进程上下文、进程堆栈、内存信息、打开的文件描述符、信号控制设置、进程优先级、进程组号、当前工作目录、根目录、资源限制、控制终端等。
子进程与父进程的区别在于:
1、父进程设置的锁,子进程不继承(因为如果是排它锁,被继承的话,矛盾了)
2、各自的进程ID和父进程ID不同
3、子进程的未决告警被清除;
4、子进程的未决信号集设置为空集。 -mickole博客
48、查看当前系统的启动时间的命令:w、top、uptime。
49、cat -n file1 file2 命令的意思是:把文件 file1 和 file2 连在一起,然后输出到屏幕上。
50、crontab 命令用来定期执行程序。时间配置段为 5 部分:f1 f2 f3 f4 f5,其中 f1 是表示分钟(0-59),f2 表示小时(0-23),f3 表示一个月份中的第几日(1-31),f4 表示月份(1-12),f5 表示一个星期中的第几天(0-6)。
51、ls是list的缩写,用来显示当前目录下面文件的信息; df是disk free的缩写,用来显示文件系统中不同磁盘的使用情况; du是disk usage的缩写,显示当前目录或者当前文件的占用的块大小; find命令作用在目录下,用来查找指定目录或者当前目录下的文件。
52、/sbin,s 就是 Super User 的意思,是 Superuser Binaries(超级用户的二进制文件)的缩写,这里存放的是系统管理员使用的系统管理程序; /lib,lib 是 Library(库) 的缩写这个目录里存放着系统最基本的动态连接共享库,其作用类似于 Windows 里的 DLL 文件。几乎所有的应用程序都需要用到这些共享库; /dev,dev 是 Device(设备)的缩写,该目录下存放的是 Linux 的外部设备,在 Linux 中访问设备的方式和访问文件的方式是相同的; /etc,etc 是 Etcetera(等等)的缩写,这个目录用来存放所有的系统管理所需要的配置文件和子目录。
53、终止一个前台进程用 ctrl+C; 终止一个后台进程:使用kill命令; - ^Z 暂停当前(前台)进程; - shutdown 关机; - halt 就是调用shutdown -h。
54、
/ 表示根目录
./ 代表当前目录
. 当前目录
.. 上级目录
~ 当前用户的默认工作目录
cd 进入用户主目录(root目录)√
cd ~ 进入用户目录(root目录)√
cd - 返回进入此目录之前所在目录
cd . 当前目录
cd .. 返回上上一级目录√
cd / 进入根目录(/这个目录包含root、etc、opt等目录,是最大的目录)√
cd ./文件夹名称 切换到当前目录的某个文件夹√
cd 文件夹名称 切换到当前目录的某个文件夹√
cd ../.. 返回上两级目录√
cd !$ 把上个命令的参数作为cd参数使用
cd /home 相当于查看有多少普通用户的家目录
55、ls命令:列出文件和文件夹,不包含 .文件名的文件和文件夹。
56、clear命令:清空窗口
57、Linux查看文件的命令
查看文件内容:
https://blog.csdn.net/pro_fan/article/details/84348793
cat <filename>:将文件的内容输出到终端。less <filename>:分页查看文件的内容,支持向前和向后翻页。more <filename>:分页查看文件的内容,只支持向前翻页。head <filename>:查看文件的前几行内容,默认为前10行。例如,以下命令查看名为
myfile.txt的文本文件的前5行内容:head -n 5 myfile.txttail <filename>:查看文件的后几行内容,默认为后10行。例如,以下命令查看名为
myfile.txt的文本文件的后5行内容:tail -n 5 myfile.txt
查看文件属性:
ls -l <filename>:查看文件的详细属性,包括文件类型、权限、拥有者、大小、创建时间等。file <filename>:查看文件类型,如文本文件、二进制文件、目录等。
查看文件状态:
stat <filename>:查看文件的状态,包括inode号、大小、创建时间、修改时间、访问时间等。du <filename>:查看文件或目录的磁盘使用情况,包括占用的磁盘空间大小和磁盘块数。
58、Linux下动态查看实时日志的命令
https://blog.csdn.net/fish_study_csdn/article/details/109344117
(1)tail -f <filename>:动态地查看文件的最后几行内容,并持续输出文件新增的内容。可以使用Ctrl+C停止输出。(最常用)
例如,可以使用以下命令查看系统日志文件/var/log/syslog的最后10行内容,并持续输出新增内容:
tail -f /var/log/syslog
(2)less +F <filename>:在less命令的基础上,使用Shift+F键可以动态地查看文件的最新内容,并持续输出文件新增的内容。可以使用Ctrl+C停止输出。
例如,可以使用以下命令查看系统日志文件/var/log/syslog的内容,并持续输出新增内容:
less +F /var/log/syslog
(3)lnav命令:可以观看和跟踪多个文件并实时显示其内容。
安装命令
$ sudo apt install lnav [On Debian&Ubuntu]
$ sudo yum install lnav [On RedHat&CentOS]
$ sudo dnf install lnav [On Fedora 22+ version]
通过发出命令同时观察两个日志文件的内容,如下例所示
$ sudo lnav /var/log/apache2/access.log /var/log/apache2/error.log
(4)multitail命令:可以实时监视和跟踪多个文件,还允许在受监视的文件中来回导航。
安装命令
$ sudo apt install multitail [On Debian&Ubuntu]
$ sudo yum install multitail [On RedHat&CentOS]
$ sudo dnf install multitail [On Fedora 22+ version]
要同时显示两个日志文件的输出,请执行以下示例中所示的命令。
$ sudo multitail /``var``/log/apache2/access.log /``var``/log/apache2/error.log
59、创建文件夹的命令
mkdir:创建一个新的空文件夹。例如,以下命令创建名为
my_folder的文件夹:mkdir my_foldermkdir -p:创建一个多级目录,如果已经存在则不会报错。例如,以下命令创建多级目录
/home/user/my_folder:mkdir -p /home/user/my_folderinstall -d`:创建一个目录,可以指定目录的权限和用户组。
例如,以下命令创建名为
my_folder的文件夹,并将其权限设置为777:install -d -m 777 my_foldercp -r:复制一个目录。
五、Kafka
1、Kafka将消息以topic为单位进行归纳;将向Kafka topic发布消息的程称为producers;将预订topics并消费消息的程序称为consumer;Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker。
2、list用于查看当前服务器中的所有 topic;create用于创建一个新的topic;delete 用于删除 topic;describe 用于查看某个 Topic 的详情。
3、Topic可以理解为一个队列,生产者和消费者面向的都是一个 topic;Consumer是消费者组的一部分,同一个组内的Consumer订阅主题相同。
4、LEO:代表当前日志文件中下一条,指的是每个副本最大的offset; ISR:代表副本同步队列; HW:指的是消费者能见到的最大的 offset,ISR 队列中最小的 LEO; AR:代表所有副本。
5、拦截器作用是发送前准备:过滤、修改消息,发送回调前:统计; 序列化器作用是对象转换成字节数组发送给 Kafka; 分区器作用是根据 key 计算 partition; 反序列化器作用是消费者用反序列化器转成对象(对应序列化器)。
6、Kafka中消息是以 topic 进行分类的,生产、消费消息,都是面向 topic的; topic是逻辑上的概念,而 partition 是物理上的概念; 每个partition对应于一个log文件,文件中存储的是producer生产的数据; Kafka采取了分片和索引机制,将每个partition分为多个segment。
7、Topic 由多个 Partition组成,Partition 由多个Segment 组成,Segment由log、index、timeindex三个文件组成。
8、Kafka通过对每个Producer分配唯一ID避免任务重复执行。
9、Zookeeper是一个分布式的协调组件,早期版本的Kafka用Zookeeper做meta信息存储,consumer的消费状态,group的管理以及 offset的值。2021年4月,Kafka官方发布了2.8.0版本,宣布Kafka正式移除了对Zookeeper的依赖,这样就无需维护Zookeeper集群,只要维护Kafka集群。
10、broker.id的默认值为0,也可以设置为其他任意的整数。但是这个值在整个kafka集群里必须是唯一的。
11、在Kafka 2.8版本前,zookeeper的作用是Kafka的元数据维护在zookeeper上。
12、OfflinePartition Leader 选举:每当有分区上线时,就需要执行 Leader 选举。所谓的分区上线,可能是创建了新分区,也可能是之前的下线分区重新上线。 ReassignPartition Leader 选举:当你手动运行 kafka-reassign-partitions 命令,或是调用Admin的alterPartitionReassignments 方法执行分区副本重分配时,可能触发此类选举。 PreferredReplicaPartition Leader 选举:当你手动运行 kafka-preferred-replica- election 命令,或自动触发了 Preferred Leader 选举时,该类策略被激活。 ControlledShutdownPartition Leader 选举:当Broker正常关闭时,该 Broker上的所有 Leader副本都会下线,因此,需要为受影响的分区执行相应的Leader选举。
13、消费者从 broker 中读取数据为pull模式; push模式不能适应消费速率不同的消费者; 消费者消息发送速率是由 broker 决定的; 如果kafka没有数据,pull模式可能会使消费者陷入循环,返回空数据,这是pull模式的不足之处。
14、Kafka单个消息的大小,默认值为1MB。如果生产者尝试发送的消息超过这个大小,不仅消息不会被接收,还会收到 broker 返回的错误消息。
15、session.timeout.ms:Coordinator 与消费者进行心跳检查时间间隔,及时发现崩溃、位移等信息,触发重平衡; heartbeat.interval.ms:心跳检查请求与响应的间隔时间,超过可能会认为消费者崩溃等,触发重平衡; message.max.bytes: Broker能够接收到的最大消息的大小,与重平衡无关; max.poll.interval.ms:消费者处理消息逻辑的最大时间,防止消费者处理任务超时未响应,超过该时间Coordinator将剔除该消费者重新平衡。
16、关于Kafka高级API与低级API: 使用高级API时,offset存储在ZooKeeper中; 使用高级API时,由Kafka的rebalance来控制消费者分配的分区; 使用低级API时,原有的Kafka策略会失效; 使用低级API时,可以自行存储offset。
17、Kafka机器数量=2*(峰值生产速度*副本数/100)+1
设用压力测试测出机器写入速度是20M/s一台,峰值的业务数据的速度是100M/s,副本数为6,预估需要部署Kafka机器数量为13。 2*(100*6/100)+1)= 13台
18、关于kafka 清理过期数据: 清理的策略包括删除和压缩; 启用压缩策略后只保留每个 key 最后一个版本的数据; log.cleanup.policy=delete启用删除策略; log.cleanup.policy=compact启用压缩策略。
19、消费者组,是多个 consumer 组成的,单个consumer 不能称为组; 同一个主题可以被多个消费者群组消费,消费者群组之间互不影响; partition是消费的基本单位,一个partition至多被一个消费者消费; 所有的消费者都属于某个消费者组,不能独立存在。
20、Replica的作用就是为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且Kafka仍然能够继续工作; 生产者发送数据的对象,以及消费者消费数据的对象都是 leader; Topic可以理解为一个队列,生产者和消费者面向的都是一个 topic; 一个topic可以分为多个 partition,每个partition是一个有序的队列。
21、活锁现象是由于持续向消费者发送心跳检查但是未及时处理,通常由于poll调用频率高导致处理记录时间长于最大间隔时间。消费者出现活锁问题时应该增加max.poll.interval.ms相关参数。
22、当日志片段大小达到指定的数量的时候(默认为1G),当前日志片段就会被关闭,一个新的日志片段被打开。
23、kafka中某一主题指定数据,默认可以被保留168个小时,也就是一周。如果指定了不止一个参数,那么kafka会优先使用具有最小值的那个参数。
24、在消息正式发送前,先执行拦截器对消息进行相应的定制化操作,然后执行序列化器将消息序列化,最后执行分区器选择对应分区,所以正确的执行顺序应该是拦截器->序列化器->分区器。
25、Kafka Manager:更多是Kafka的管理,提供了简单的瞬时指标监控; Kafka Monitor:LinkedIn开源的免费框架,支持对集群进行系统测试,并实时监控测试结果; CruiseControl:LinkedIn公司开源的监控框架,用于实时监测资源使用率; Kafka的零拷贝技术,主要用于数据传输,与监控无关。
26、一个 topic 的每个分区都有若干个副本,一个 leader和若干个 follower; leader:生产者发送数据的对象,以及消费者消费数据的对象都是 leader; follower:实时从 leader中同步数据,保持数据的同步,而没有延迟。
27、Kafka能够持久化日志,这些日志可以被重复读取和无限期保留; 流式处理是指实时的处理一个或者多个事件流,Kafka支持实时的流式处理。 28、Controller 会向Broker发送三类请求,分别是LeaderAndIsrRequest、StopReplicaRequest和UpdateMetadataRequest。
LeaderAndIsrRequest:告诉 Broker 相关主题各个分区的Leader副本位于哪台Broker 上、ISR中的副本都在哪些Broker上;
StopReplicaRequest:告知指定Broker停止它上面的副本对象,该请求甚至还能删除副本底层的日志数据;
UpdateMetadataRequest:该请求会更新Broker上的元数据缓存。
29、ActiveControllerCount是Broker端监控指标,不是发送的请求。
30、Kafka消费者分区分配策略:Range分配策略、RoundRobin分配策略、Sticky分配策略。 31、对Kafka而言,request.required.acks 有三个值 0,1,-1。
0:生产者不会等待 broker的ack,这个延迟最低但是存储的保证最弱当 server 挂掉的时候就会丢数据;
1:服务端会等待ack值 leader副本确认接收到消息后发送ack,但是如果leader挂掉后他不确保是否复制完成新 leader 也会导致数据丢失;
-1:在1的基础上服务端会等所有的 follower的副本受到数据后才会受到leader发出。
32、Producer 发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了两个线程main 线程和 Sender 线程,以及一个线程共享变量RecordAccumulator。main 线程将消息发送RecordAccumulator,Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka broker。
六、HTML
1、当margin属性为四个参数时,分别代表:上、右、下、左外边距。
2、 output:这个标签用来定义不同类型的输出,比如脚本的输出。 placeholder:该提示会在输入字段为空时显示,并会在字段获得焦点时消失。 autofocus:当页面加载时 input 元素应该自动获得焦点。 required:如果使用该属性,则字段是必填(或必选)的。
3、Web Storage实际上由两部分组成:sessionStorage与localStorage。 sessionStorage用于本地存储一个会话(session)中的数据,这些数据只有在同一个会话中的页面才能访问并且当会话结束后数据也随之销毁。因此sessionStorage不是一种持久化的本地存储,仅仅是会话级别的存储。 localStorage用于持久化的本地存储,除非主动删除数据,否则数据是永远不会过期的。
4、
块级元素:form,table,p、div、h1~h6、ul、ol、li
行级元素(行内元素):<a>、<span>、<img>、<em>、<strong>、<input>
5、
<article> 标签:用于文本或嵌入内容、开始和结束标记都是必需的、可以用来提供作者信息。
6、
<meter> 元素表示已知范围内的标量值或阶乘值。它包括全局属性,如min、max、value、optimal、low、high、form等。
7、onclick():鼠标事件---》鼠标点击触发; onblur():表单事件---》元素失去焦点触发; onfocus():表单事件---》元素获得焦点时触发。
8、DHTML是Dynamic HTML的简称,就是动态的HTML(标准通用标记语言下的一个应用),是相对传统的静态的html而言的一种制作网页的概念。 DHTML只是HTML、CSS和客户端脚本的一种集成,即一个页面中包括html+css+javascript(或其它客户端脚本) html+css+javascript(或其他脚本)的优点:html确定页面框架,css和脚本决定页面样式、动态内容和动态定位。
9、ele.clientWidth = 宽度 + 左右padding ele.offsetWidth = 宽度 + 左右padding + border ele.scrollTop = 被卷去的上侧距离 ele.scrollHeight = 自身实际的高度(不包括边框)
10、date 选取日、月、年 month 选取月和年 week 选取周和年 time 选取时间(小时和分钟)
11、td 的 colspan属性代表所占列数, rowspan 属性代表所占行数。 首先看有几行,几行只要通过tr就可以判断,题目里有3个tr,所以是3行。 其次看有几列,列数是看有最多td的那一行,所以是2列。
12、在HTML5中,为input元素新增了以下一些type属性值: color:用于指定颜色的控件。
date:用于输入日期的控件(年,月,日,不包括时间)。
month:用于输入年月的控件,不带时区。
week:用于输入一个由星期-年组成的日期,日期不包括时区
time:用于输入不含时区的时间控件。
datetime:基于UTC时区的日期时间输入控件(时,分,秒及几分之一秒)。
datetime-local:用于输入日期时间控件,不包含时区。
email:用于应该包含 e-mail 地址的输入域。在提交表单时,会自动验证 email 域的值。
number: 用于应该包含数值的输入域。只能输入数字
range:用于应该包含一定范围内数字值的输入域。range 类型显示为滑动条。
search:用于输入搜索字符串的单行文本字段。换行会被从输入的值中自动移除。
tel:用于输入电话号码的控件。在移动端输入会显示数字键盘,PC端无效果
url:用于编辑URL的字段。
13、alt属性提供替代图片的信息,使屏幕阅读器能获取到关于图片的信息。
14、link 属于 XHTML 标签,除了加载 CSS 外,还能用于定义 RSS,定义 rel 连接属性等作用;而 @import 是 CSS 提供的,只能用于加载 CSS; @import 是 CSS2.1 提出的,只在 IE5 以上才能被识别,而 link 是 XHTML 标签,无兼容问题; link 支持使用 JS 控制 DOM 去改变样式,而 @import 不支持; 加载页面时,link标签引入的 CSS 被同时加载;@import引入的 CSS 将在页面加载完毕后被加载。
15、一个页面不可以存在多个title元素。
16、">"与"+"的规则如下:
div > p:选择父元素是 <div> 的所有 <p> 元素
div + p:选择紧跟 <div> 元素的首个 <p> 元素
17、iframe是用来在网页中插入第三方页面,早期的页面使用iframe主要是用于导航栏这种很多页面都相同的部分,这样在切换页面的时候避免重复下载; iframe的创建比一般的DOM元素慢了1-2个数量级; iframe标签会阻塞页面的的加载。
18、slideUp()和slideDown都是jQuery函数,slideUp()通过使用滑动效果,隐藏被选元素,如果元素已显示出来的话。slideDown() 方法通过使用滑动效果,显示隐藏的被选元素。
19、JSON相对于XML来讲,数据的体积小,传递的速度更快些; JSON与JavaScript的交互更加方便,更容易解析处理,更好的数据交互; JSON的速度一般要快于XML; JSON的描述性没有XML好。
20、P元素不能包含div; li元素的祖先元素可能是li,但父元素不可能是li; a元素可以包含img
七、CSS
八、JavaScript
九、Vue
1、所谓组件化,就是把页面拆分成多个组件 (component),每个组件依赖的 CSS、JavaScript、模板、图片等资源放在一起开发和维护; vue的组件之间可以进行通信; 组件化能提高开发效率,方便重复使用,简化调试步骤,提升项目可维护性,便于多人协同开发。
2、vue-router可以实现重定向,通过routes的redirect属性配置来完成; vue-router可以通过配置实现路由懒加载。
3、keep-alive:缓存子组件,被包裹的子组件会多出两个生命周期:activated、deactivated; 当组件在keep-alive内被切换时,它的mounted和unmounted生命周期钩子会被activated和、deactivated代替。
4、
Vue路由的跳转方式有route-link、this.$router.push()、this.$router.replace()、this.$router.go()等,但是没有this.$router.jump()
5、父子组件生命周期的执行顺序是父亲beforecreate、父亲created、父亲beforeMount、孩子beforecreate、孩子created、孩子beforeMount、孩子mounted、父亲mounted、父亲beforeDestroy、孩子beforeDestroy、孩子destroyed、父亲destroyed。
6、Vue 中通过给元素添加ref属性绑定DOM元素,通过this.$refs获取。
7、绑定事件有两种方式:第一种,通过v-on指令。二种,通过@语法糖。
8、v-model: 双向绑定
v-on(@):绑定事件
v-bind(:): 绑定dom
9、对数组的操作: push()在该数组最尾添加新的元素,然后返回更新后的数组长度,方法将改变原始数组的长度; shift()删除该数组第一个元素,并且把该数组剩下的元素索引往前挪一位,然后返回删除的元素,方法将改变原始数组的长度; reverse()反转该数组中元素的顺序,方法将改变原始数组; concat()把两个以上的数字连接起来,该方法不会改变现有的数组,而仅仅会返回被连接数组的一个副本; push(),shift(),reverse()改变原数组,会触发视图跟新; concat()不更改数组,会返回新数组,因此没有替换原数组,不触发视图更新,要用新数组替换原数组才能实现视图更新。
10、路由模式: vue-router有两种模式,history和hash模式; hash模式是通过onhashchange事件,监听url的修改; history通过H5提供的API history.pushState 和 history.pushState实现跳转且不刷新页面; history模式需要后端进行配合。
11、全局路由守卫的钩子函数有: beforeEach(全局前置守卫)、beforeResolve(全局解析守卫)、afterEach(全局后置守卫)
12、Vue的特性有轻量级、双向数据绑定、组件化、数据驱动试图、指令、过滤器、路由、计算属性等。
13、Vuex属性包含state、mutations、actions、getters、modules。
十、计算机网络
十一、操作系统
1、虚拟内存
虚拟内存是计算机系统内存管理的一种技术,使得应用程序认为它拥有连续可用的内存; 实现进程地址空间隔离; 虚拟内存和物理内存的映射通过页表来实现。
2、
反码:正数的反码为其本身,负数的反码是其原码除了符号位外全部按位取反。 补码:正数的补码为其本身,负数的补码是将其原码的反码+1。
3、&&是逻辑与 即判断&&两侧的表达式是否都为真,都为真则此&&表达式值为真;& 是按位与 即将&两侧的数用二进制展开,每一位都求与运算(二进制与运算,跟逻辑与差不多),最后得到的二进制数即为结果;逻辑与结果只讲真和假,而按位与得出的却是实实在在的一个数
4、
&:有0则0|:有1则1^:相同为0,不同为1
十二、算法
1、
输入数字进行比较
来自斐波那契数列
class Solution {
public int fib(int n) {
int f[]={0,1,2,3,4,5,6,7,8,9};
return f[n];
}
}
class Solution {
public int fib(int n) {
int f[]={0,1,1,2,3,5,8,13,21,34,55,89,144,233,377,610,987,1597,2584,4181,6765,10946,17711,28657,46368,75025,121393,196418,317811,514229,832040,1346269,2178309,3524578,5702887,9227465,14930352,24157817,39088169,63245986,102334155,165580141,267914296,433494437,701408733,134903163,836311896,971215059,807526948,778742000,586268941,365010934,951279875,316290802,267570670,583861472,851432142,435293607,286725742,722019349,8745084,730764433,739509517,470273943,209783453,680057396,889840849,569898238,459739080,29637311,489376391,519013702,8390086,527403788,535793874,63197655,598991529,662189184,261180706,923369890,184550589,107920472,292471061,400391533,692862594,93254120,786116714,879370834,665487541,544858368,210345902,755204270,965550172,720754435,686304600,407059028,93363621,500422649,593786270,94208912,687995182};
return f[n];
}
}
2、
1、Java去掉字符串空格
String str = " hi world ~ "; str.trim(); //去掉首尾空格 str.replace(" ",""); //去除所有空格,包括首尾、中间 str.replaceAll(" ", ""); //去掉所有空格,包括首尾、中间 str.replaceAll(" +",""); //去掉所有空格,包括首尾、中间 str.replaceAll("\\s*", ""); //可以替换大部分空白字符, 不限于空格 str.split("\\s+"); //去掉字符串中间的多余空格,只留一个空格2、有限状态机是一种用来进行对象行为建模的工具,作用是描述对象在它的生命周期内所经历的状态序列,以及如何响应来自外界的各种事件。我们现在所说的状态机一般是有限状态机(FSM)的简称,限状态机(Finite State Machine),是一种应用非常广泛的软件设计模式(Design Pattern)。
3、
来自9. 回文数(简单)
知识点:
1、substring(star,end)包左不包右
s2=s.substring((s.length()/2)+1); 表示从(s.length()/2)+1开始截取到字符串结束为一个子字符串
2、sb.reverse()是倒转字符串。 String.valueOf(x) 将 int 变量 x 转换成字符串
StringBuffer sb = new StringBuffer(String.valueOf(x)); sb.reverse().toString().equals(String.valueOf(x));
4、
来自剑指 Offer 58 - I. 翻转单词顺序(简单)
知识点:
1、去掉字符串中间的多余空格,只留一个空格
s = s.replaceAll(" +"," ");或者str.split("\\s+");2、
Collections.reverse(List list)这个方法的功能是实现List集合排序的反转。比如集合原顺序是["A","B","C","D","E"],调用reverse方法后,集合的排序就变成了["E","D","C","B","A"]。
List<String> wordList = Arrays.asList(s.split("\\s+")); Collections.reverse(wordList);
5、
来自118. 杨辉三角(简单)
知识点:
1、获取ArrayList的最后一个元素
ArrayList<Integer> row = new ArrayList<>();row.get(size()-1);添加元素:row.set(index,element);
6、
来自13. 罗马数字转整数(简单)
知识点:
HashMap
Map<Character, Integer> symbolValues = new HashMap<Character, Integer>()
7、
来自21. 合并两个有序链表(简单)
知识点:
单链表表长有 list1.length 属性吗 无 如何往一个链表中添加元素?list1.add() ??? 无
8、
来自:剑指 Offer 06. 从尾到头打印链表(简单)
知识点:
Java栈和LinkedList的知识: stack.removeLast(); stack.addLast(); stack.size();
9、
来自:剑指 Offer 24. 反转链表(简单)
知识点:
1、迭代与递归的区别
递归,就是在运行的过程中调用自己。构成递归需具备的条件: 1. 子问题须与原始问题为同样的事,且更为简单; 2. 不能无限制地调用本身,须有个出口,化简为非递归状况处理。 相同点: 递归和迭代都是循环的一种。 不同点: 1、程序结构不同 递归是重复调用函数自身实现循环。迭代是函数内某段代码实现循环。 其中,迭代与普通循环的区别是:迭代时,循环代码中参与运算的变量同时是保存结果的变量,当前保存的结果作为下一次循环计算的初始值。 2、算法结束方式不同 递归循环中,遇到满足终止条件的情况时逐层返回来结束。迭代则使用计数器结束循环。 当然很多情况都是多种循环混合采用,这要根据具体需求。 3、效率不同 在循环的次数较大的时候,迭代的效率明显高于递归
10、
来自:Offer 15. 二进制中1的个数(简单)
知识点:
1、Integer类中的bitCount()方法用于获取一个int中二进制位为1的个数。
2、Java 中无符号右移为 ">>>"
11、
来自:Offer17
知识点:
1、 int[] res = new int[x-1]; //定义一长度为x-1的数组
12、
来自Offer19
知识点:
1、Java中的matches() 方法
matches() 方法用于检测字符串是否匹配给定的正则表达式。
2、动态规划有时候使用一维数组有时候使用二维数组。
13、
来自32 - I. 从上到下打印二叉树(中等)
知识点:
1、queue.poll(); 返回队首元素的同时删除队首元素,队列为空时返回NULL。 queue.remove(); 返回队首元素的同时删除队首元素,队列为空时抛出NPE空指针异常。 queue.element(); 不会删除队首元素,只返回查看队首元素的值。
2、
创建队列
Queue<TreeNode> queue=new LinkedList<>();创建List集合Integer型
List<Integer> list=new ArrayList<Integer>();创建规定长度的数组
int[] res = new int[100];2、Java8之list.stream的常见使用
public static void main(String[] args) { List<Student> list = Lists.newArrayList(); list.add(new Student("测试", "男", 18)); list.add(new Student("开发", "男", 20)); list.add(new Student("运维", "女", 19)); list.add(new Student("DBA", "女", 22)); list.add(new Student("运营", "男", 24)); list.add(new Student("产品", "女", 21)); list.add(new Student("经理", "女", 25)); list.add(new Student("产品", "女", 21)); //求性别为男的学生集合 List<Student> l1 = list.stream().filter(student -> student.sex.equals("男")).collect(toList()); //map的key值true为男,false为女的集合 Map<Boolean, List<Student>> map = list.stream().collect(partitioningBy(student -> student.getSex().equals("男"))); //求性别为男的学生总岁数 Integer sum = list.stream().filter(student -> student.sex.equals("男")).mapToInt(Student::getAge).sum(); //按性别进行分组统计人数 Map<String, Integer> map = list.stream().collect(Collectors.groupingBy(Student::getSex, Collectors.summingInt(p -> 1))); //判断是否有年龄大于25岁的学生 boolean check = list.stream().anyMatch(student -> student.getAge() > 25); //获取所有学生的姓名集合 List<String> l2 = list.stream().map(Student::getName).collect(toList()); //求所有人的平均年龄 double avg = list.stream().collect(averagingInt(Student::getAge)); //求年龄最大的学生 Student s = list.stream().reduce((student, student2) -> student.getAge() > student2.getAge() ? student:student2).get(); Student stu = list.stream().collect(maxBy(Comparator.comparing(Student::getAge))).get(); //按照年龄从小到大排序 List<Student> l3 = list.stream().sorted((s1, s2) -> s1.getAge().compareTo(s2.getAge())).collect(toList()); //求年龄最小的两个学生 List<Student> l4 = l3.stream().limit(2).collect(toList()); //获取所有的名字,组成一条语句 String str = list.stream().map(Student::getName).collect(Collectors.joining(",", "[", "]")); //获取年龄的最大值、最小值、平均值、求和等等 IntSummaryStatistics intSummaryStatistics = list.stream().mapToInt(Student::getAge).summaryStatistics(); System.out.println(intSummaryStatistics.getMax()); System.out.println(intSummaryStatistics.getCount()); } @Data @AllArgsConstructor static class Student{ String name; String sex; Integer age; }
14、
来自:31. 栈的压入、弹出序列(中等)
知识点:
1、stack.peek() peek()方法用于从此Stack中返回顶部元素,并且它不删除就检索元素。
2、stack.isEmpty(); isEmpty()就是很简单的判断栈中元素是否等于0
stack.Empty(); empty()则是判断size()是否等于0
15、
知识点:Map<K,V> K:键的类型;V:值的类型
16、
来自Offer
知识点:
1、Queue 中 add() 和 offer()都是用来向队列添加一个元素。 在容量已满的情况下,add() 方法会抛出IllegalStateException异常,offer() 方法只会返回 false 。
17、
来自Offer
知识点:
1、return new int[0]; 表示返回空数组 [] new int[1] 表示数组[0]
new int[2] 表示数组[0,0]
18、
来自Offer
知识点:
1、什么是堆:堆是一种满足以下条件【堆中的每一个节点值都大于等于(或小于等于)子树中所有节点的值。或者说,任意一个节点的值都大于等于(或小于等于)所有子节点的值。】的树。
2、大顶堆:通俗意义上来讲就是大的数放顶上,小的数放下面、也就是降序。所以需要保证每一个父节点都大于他的两个子节点。
3、小顶堆:和大顶堆相反,小的数放上面,大的数放下面,也就是升序、所以需要保证每一个父节点都小于他的两个子节点。
4、堆在存储的时候并不是使用树形结构存储的,而是使用数组的形式。
5、堆是另一种与优先队列不同的数据结构,一般来说,堆是用来实现优先队列的,非严格来说,优先队列可以等同于堆,因为堆是用来实现优先队列的,所以优先队列的大部分内容都是在讨论堆,但不要忘记主要内容还是优先队列。
19、
来自Offer
知识点:
语法:
(parameters) -> expression 或 (parameters) ->{ statements; }例子:
// 1. 不需要参数,返回值为 5 () -> 5 // 2. 接收一个参数(数字类型),返回其2倍的值 x -> 2 * x // 3. 接受2个参数(数字),并返回他们的差值 (x, y) -> x – y // 4. 接收2个int型整数,返回他们的和 (int x, int y) -> x + y // 5. 接受一个 string 对象,并在控制台打印,不返回任何值(看起来像是返回void) (String s) -> System.out.print(s)
20、
来自每日一题7-7
知识点:
1、Java中的字典树:又叫单词查找树、TrieTree,是一种树形结构,主要思想是利用字符串的
公共前缀来节约存储空间。
21、
来自 LeetCode100 461. 汉明距离
知识点:
1、bitCount() 计算一个 int,long 类型(byte,short,char,int 统一按照int方法计算)的数值在二进制下 “1” 的数量。